


7. Unindo tabelas com o R
Já vimos nos tópicos anteriores que os dados de vigilância em saúde pública podem ser provenientes de diversas fontes, tais como buscas em prontuários, laboratórios públicos ou privados, sistemas de informação diversos, etc. O profissional de vigilância em seu dia a dia deve então consultar diversas fontes de dados para a construção de sua rotina de avaliação dos agravos, doenças e eventos de saúde pública.
É comum que para realizar uma investigação você necessite consultar os resultados de exames laboratoriais ou o cadastro de endereço de um paciente para concluir sua notificação garantindo a qualidade e veracidade de seus dados. Por vezes, é necessário unir planilhas ou relacioná-las para trabalhar em conjunto dando mais velocidade a este tipo de ação.
Muitas vezes na vigilância cruzamos a tabela Classificação Brasileira de Ocupações (CBO) fornecida pelo Datasus com os códigos de profissão notificados no Sinan NET, ou mesmo a tabela de CID-10 com as ocorrências de óbito (SIM - Sistema de Informações de Óbitos) do seu município. Este é um trabalho exaustivo e para alguns agravos se torna impossível, como durante a pandemia de Covid-19 em que o volume de notificações é enorme. Neste tópico iremos aprender algumas das ações mais comuns de relacionamento entre bancos de dados.
A união ou junção de bancos de dados é um procedimento realizado sempre entre duas ou mais bases. Para essa ação é necessário que os bancos de dados que serão unidos contenham variáveis que identifiquem unicamente cada registro (linha) para que possam ser usadas para conectá-las. Essas variáveis são chamadas chaves (em inglês, keys). Outra importante necessidade é que estas variáveis possuam o mesmo tipo de dados em ambas as tabelas (numérico, texto, etc).
Em junções simples de bases, basta uma única chave para se identificar o registro e seguir com a união conforme a Figura 8.
Figura 8: Relação de união entre a tabelas de cadastro de pacientes e a tabela de municípios.
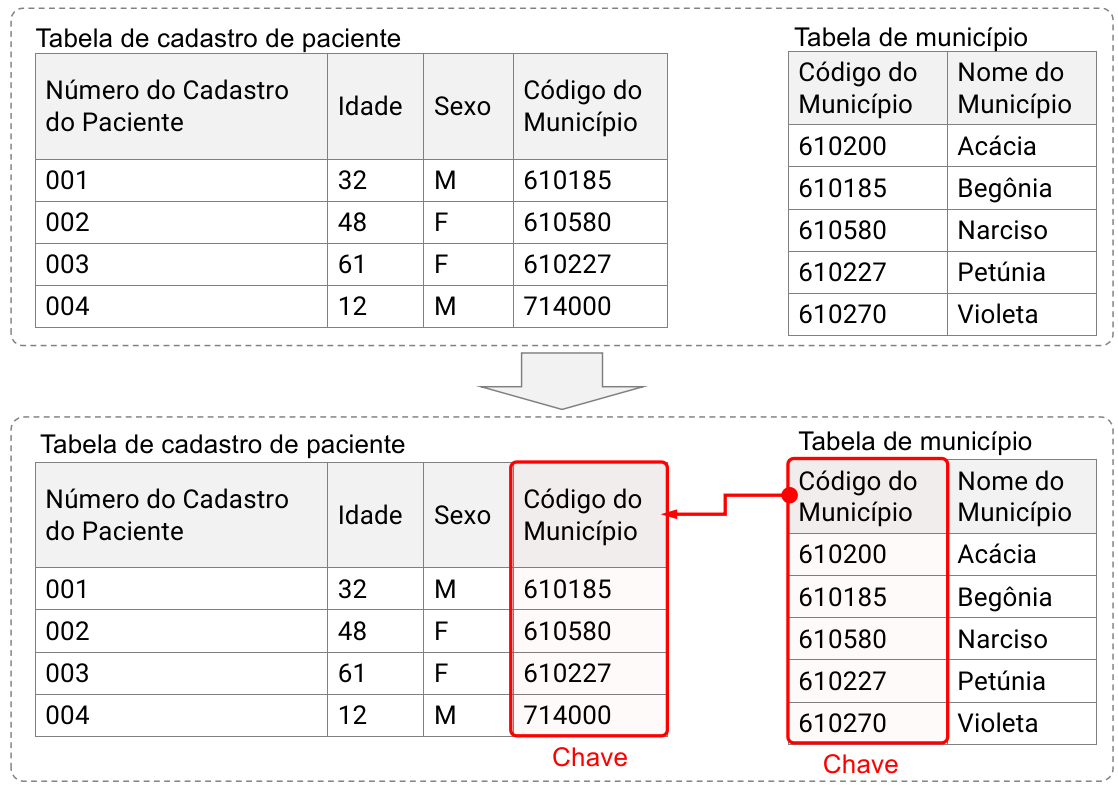
Perceba que temos duas tabelas: a da esquerda é o cadastro de
paciente e a da direita o cadastro de municípios no Estado de Rosas. Na
primeira tabela, além de dados pessoais dos pacientes, há o código do
município onde o paciente reside, mas não há o nome do município. Na
tabela da direita há o código e o nome do município, mas não há dados
dos pacientes. Neste caso podemos relacioná-las utilizando a chave
(key) em comum: o Código do Município.
Dessa forma, a tabela de paciente se conecta a de município por uma
única variável, a chave Código do município. O resultado
desse processo acrescenta mais uma coluna com o nome do município, como
pode ser visto na Figura 9.
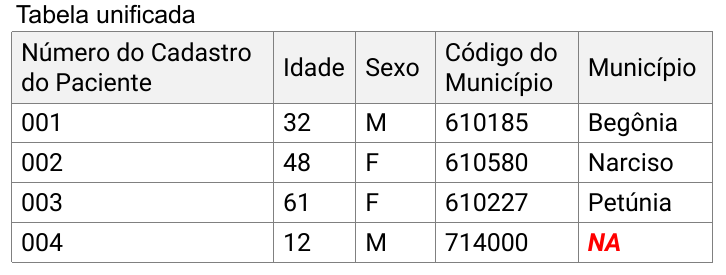
Figura 9: Tabela unificada entre a tabela de cadastro de pacientes e de municípios.
7.1 Tipos de cruzamento de dados (Join)
No exemplo anterior, percebemos que, após a união, a tabela de
pacientes, localizada à esquerda, recebeu uma nova coluna e manteve
todos os seus registros, embora um registro não tenha sido encontrado na
tabela de município. Já na tabela de municípios, à direita, restaram
aqueles em comum com a tabela de pacientes. Nesta ação utilizamos a
função join do inglês, uma operação de junção que combina
colunas de uma ou mais tabelas em um banco de dados relacional. Agora,
vamos aprender os tipos de join presentes no pacote
dplyr.
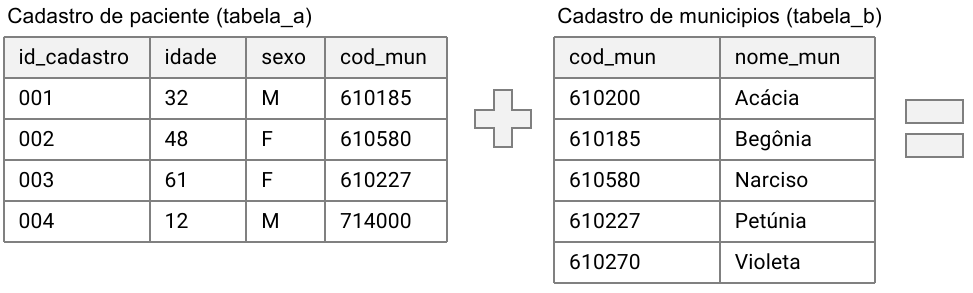
Observe o procedimento de união das duas tabelas apresentadas na
Figura 10. A tabela de cadastros de paciente, que chamaremos de
tabela_a, e a tabela de municípios, que chamaremos de
tabela_b, serão unidas utilizando a chave
cod_mun. Vamos destacar os principais tipos de união, suas
descrições detalhando o resultado dos procedimentos e um exemplo de uso
da função correspondente no dplyr.
Figura 10: União de tabelas.

Lembre-se que as funções join possuem os mesmos argumentos, sendo os principais:
- os nomes das tabelas a serem unidas, e
- a indicação da variável chave no argumento
by.
Agora iremos cruzar os nomes dos municípios contidos no banco de
dados {tabela_municipios.xlsx} com os códigos de municípios
notificando agravos no Estado de Rosas por meio do Sinan Net
{NINDINET.dbf}.
Para isto, realizaremos o cruzamento do objeto
{base_menor}, criado a partir do banco de dados
{NINDINET.dbf}, com a tabela de municípios
{tabela_municipios.xlsx}, exportada do IBGE, disponível no
menu lateral “Arquivos”, no Ambiente Virtual deste curso.
Vamos lá, primeiro vamos importar o banco de dados com nome dos
municípios de Rosas e seus respectivos códigos. Acompanhe os
scripts abaixo e replique-o em seu RStudio.
# Importando o banco de dados {`tabela_municipios.xlsx`} para o `R`
tabela_municipios <- read_excel("Dados/tabela_municipios.xlsx",
sheet = 1,
skip = 0)A seguir, iremos realizar a união das tabelas considerando que as
duas possuem uma variável em comum: o código de identificação do
município. Para {base_menor} esta variável possui o nome
ID_MN_RESI, enquanto para {tabela_municipios}
esta variável possui o nome ID_MUNICIPIO. Antes de fazermos
a união, precisamos checar se são compatíveis, isto é, se são o mesmo
tipo de variável.
Acompanhe o script abaixo e replique-o em seu computador:
# Verificando o tipo de variável na coluna `ID_MN_RESI` do NINDINET
class(base_menor$ID_MN_RESI)#> [1] "integer"# Verificando o tipo de variável na coluna `ID_MUNICIPIO` da tabela de municípios
# do IBGE
class(tabela_municipios$ID_MUNICIPIO)#> [1] "character"Perceba no output que na {base_menor} a coluna
com os códigos de municípios é um número inteiro (integer)
e que para o objeto {tabela_municipios} obtemos uma
variável em formato de texto (character).
Para evitar erros de compatibilidade, vamos transformar a coluna
ID_MUNICIPIO de {tabela_municipios} também em
uma variável numérica. Observe os códigos abaixo, e replique-os em seu
RStudio:
# Transformando apenas a variável `ID_MUNICIPIO` do data.frame {`tabela_municipios`}
# e utilizando a função `as.integer()` para torná-la do tipo numérica
tabela_municipios$ID_MUNICIPIO <- as.integer(tabela_municipios$ID_MUNICIPIO)Pronto! Agora, já é possível realizar a união das tabelas utilizando
as colunas com os códigos dos municípios de forma segura. Continue
acompanhando o script abaixo e replique-o em seu
RStudio:
left_join(
# Unindo a tabela {`base_menor`}
x = base_menor,
# com a tabela {`tabela_municipios`}
y = tabela_municipios,
# Selecionando as colunas `ID_MN_RESI` e `ID_MUNICIPIO` para unir os bancos de
# dados
by = c("ID_MN_RESI" = "ID_MUNICIPIO")) |>
# Visualizando a união realizada
head()#> DT_NOTIFIC DT_NASC CS_SEXO CS_RACA ID_MN_RESI ID_AGRAVO ID_UF NM_ESTADO
#> 1 2012-04-11 2012-04-04 M 4 610213 A509 33 Rosas
#> 2 2010-09-17 1988-04-23 M 1 610213 W64 33 Rosas
#> 3 2010-10-19 1971-03-25 M NA 610250 X58 33 Rosas
#> 4 2008-04-14 1928-05-29 F 4 610213 A90 33 Rosas
#> 5 2011-06-20 2002-09-18 M 4 610250 B19 33 Rosas
#> 6 2008-02-12 1953-08-01 F 9 610213 A90 33 Rosas
#> NM_MUNICIPIO
#> 1 Prímula
#> 2 Prímula
#> 3 Papoila
#> 4 Prímula
#> 5 Papoila
#> 6 PrímulaPronto. Agora temos uma tabela {base_menor} com a
inclusão dos nomes de todos os municípios que tiveram pessoas
notificadas.