


5. Incluindo códigos ao relatório
O grande diferencial dos arquivos escritos em Rmarkdown
é a possibilidade de incluir trechos de códigos (em inglês: code
chunks) no texto. Esta etapa é fundamental para que nosso relatório
possua dados, que podem ser reprodutíveis e sempre atualizados. Dentro
dos chunks iremos inserir códigos que produzam análises,
tabelas e figuras, tornando nosso documento de texto mais interessante e
complexo. Nesta subseção, iremos aprender a mesclar esses trechos de
códigos em nossos documentos, personalizá-los. Assim, iremos transformar
nosso arquivo .Rmd em um arquivo que poderá ser enviado
para o secretário de saúde do Estado de Rosas, para a imprensa e até
mesmo disponibilizado de forma online em um
website.
Vamos lá!
Até aqui vimos que os chunks são trechos para inclusão de
código em R. Esses códigos deverão ser delimitados no
início da sua escrita por três acentos graves ( ``` )
seguido do código {r}
(uma letra "r" minuscula entre colchetes). Para encerrar a
inserção dos códigos basta novamente você incluir os três acentos graves
( ``` ). Elas irão indicar a finalização do trecho de
código.
Pareceu difícil? Calma, iremos detalhar passo a passo nesta seção do
curso. Lembre-se que no seu texto o chunk será indicado por uma
área sombreada (Figura 38). Essa área avisa que o código a ser
interpretado para o relatório está na linguagem R.
Figura 38: Área do script para inserção de códigos.

Tente se lembrar da Figura 5 no início deste curso ou volte a unidade
dois do curso e observe o chunk destacado em
a. Ao clicar nas pequenas setas ao lado do número das
linhas no RStudio (item b do desenho),
você ocultará todo o código neste trecho. Veja na Figura 39 como podemos
facilitar a escrita do documento como um todo quando estamos escrevendo
um arquivo .Rmd. A possibilidade de ocultar o
chunk um recurso interessante que pode facilitar a visualização
do documento.
Figura 39: Ocultando o chunk do scriptRmarkdown.

Agora observe também que no item b da Figura 38 você
visualiza três símbolos diferentes. Ao clicar na roda dentada (Figura
40), o RStudio irá abrir um pequeno menu com opções para
este código. Observe e replique esta etapa em seu computador.
Figura 40: Configurando o chunk em um scriptRmarkdown.
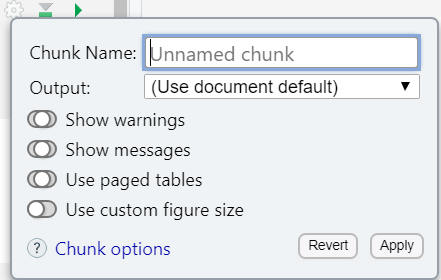
Neste menu é possível nomear o trecho de código em Chunk
Name, se assim desejar. Caso decida nomear estes trechos de
códigos, faça com atenção pois para que o chunk funcione sem
erros não poderá haver nomes repitidos. Se houver um nome repetido o
R irá apresentar erro no momento de renderização do
arquivo, lhe impedindo de gerar o documento final.
Agora observe a caixa de nome output na Figura 40. Ela permitirá que você escolha cinco possibilidades para configuração de exibição do código no momento da renderização para o documento final. Observe esta etapa na Figura 41 e a descrição das opções na Tabela 3 abaixo.
Figura 41: Configurando o output do chunk em um script Rmarkdown.

Tabela 3: Configurando o output do chunk em um script Rmarkdown.

Ao selecionar cada uma dessas opções, você irá observar que um novo
argumento irá aparecer na primeira linha do seu trecho
de código (ao lado do trecho entre colchetes {r}). Por
exemplo, após incluirmos o nome para este trecho de código como
“código 1”, e selecionar “Show output
only”, obteremos um chunk semelhante à Figura 42.
Repita esta etapa em seu RStudio e visualize em seu
computador.
Figura 42: Configurando ”Show output only”** do
chunk em um script Rmarkdown.**

Agora vamos utilizar esses argumentos para customizar como nossos
trechos de chunks serão inseridos no documento final
(renderizado). Lembre-se, que a estrutura entre as chaves deverá seguir
a seguinte lógica:
{r nome do trecho de código, argumento 1, argumento 2, ...}.
- O echo: Indica se o código irá aparecer no
documento final, enquanto sempre mostra o output . O valor do
echo, por padrão, permenece como sendo igual a
TRUE. Neste caso, o código e o output são apresentados no documento final. Observe o código no arquivo.Rmdconforme Figura 43:
Figura 43: Configurando echo** escolhida para o chunk em um script Rmarkdown.**

Agora veja como visualizamos em um arquivo renderizado conforme
Figura 44. Replique esta etapa em seu RStudio e renderize
seu código.
Figura 44: Renderizando a configuração echo = TRUE** escolhida para o chunk em um script Rmarkdown.**

Fica bem interessante, não é mesmo? Agora, se você optar para o valor
de echo = FALSE, apenas o output é mostrado no
documento final, e o código em R fica oculto, conforme a
Figura 45.
Figura 45: Renderizando a configuração echo = FALSE** escolhida para o chunk em um script Rmarkdown.**

- O include: Indica se o código irá aparecer no
documento final. Por padrão, o seu valor é igual a
TRUE. Neste caso, o código será mostrado como o exemplo na Figura 46. Veja esta configuração no arquivo.Rmd:
Figura 46: Configurando include = TRUE** escolhida para o chunk em um script Rmarkdown.**

Agora veja como visualizamos em um arquivo renderizado (Figura 47).
Replique o código desta etapa em seu RStudio e
renderize-o.
Figura 47: Renderizando a configuração include = TRUE** escolhida para o chunk em um script Rmarkdown.**

Quando definido o argumento include igual a
FALSE, ele irá ocultar do documento final o código
em R e o seu output. Note que este
comportamento se diferencia do comando echo, que quando
definido como FALSE, omite apenas o código, mas apresenta o
output no documento final.

Embora, tenha sido possível definir se o código ou output poderiam ser ocultados ou não utilizando os comandos anteriores. É importante que você saiba que os códigos dentro do trecho sempre são executados. O que muda é se iremos ou não visualizá-lo quando o documento é renderizado.
- O eval: Indica se o código deve ser executado
(Figura 48). Com o comando
evalé possível escolher se o código deverá ser executado no momento em que o documento é renderizado (gerado) ou não. Por padrão, o seu valor é igual aTRUE. Veja como fica o código no arquivo.Rmdvisualizado na Figura 48:
Figura 48: Configurando eval = TRUE** escolhida para o chunk em um script Rmarkdown..**

Por sua vez, é possível também configurar o eval e
definir que o código apareça no documento final, mas sem que seja
executado conforme a Figura 49 dando valor FALSE a ele.
Figura 49: Renderizando eval = FALSE** escolhida para o chunk em um script Rmarkdown.**

Agora veja como visualizamos em um arquivo renderizado conforme
Figura 50. Replique o código desta etapa em seu RStudio e
renderize-o.
Figura 50: Renderização Renderizando eval = FALSE** escolhida para o chunk em um script Rmarkdown.**
Além destes comandos, é possível definir se mensagens do console irão ser mostradas no documento final, conforme a Tabela 4:
Tabela 4: Argumentos de configuração das mensagens do console no script em um script Rmarkdown.

Ainda temos alguns trecho de código para detalhar no arquivo
.Rmd então vamos lá. Continuaremos aprendendo sobre os
componentes presentes no destaque b da Figura 38. Você
verá o ícon RUN: o símbolo  .
.
Este símbolo irá executar na própria sessão do RStudio o
código presente no trecho de código escolhido. Esta função facilita com
que o script em R digitado possa ser testado antes
da geração do documento final. Veja na Figura 51 como seria executar um
código no chunk.
Figura 51: Tela de executando do chunk em um script Rmarkdown.
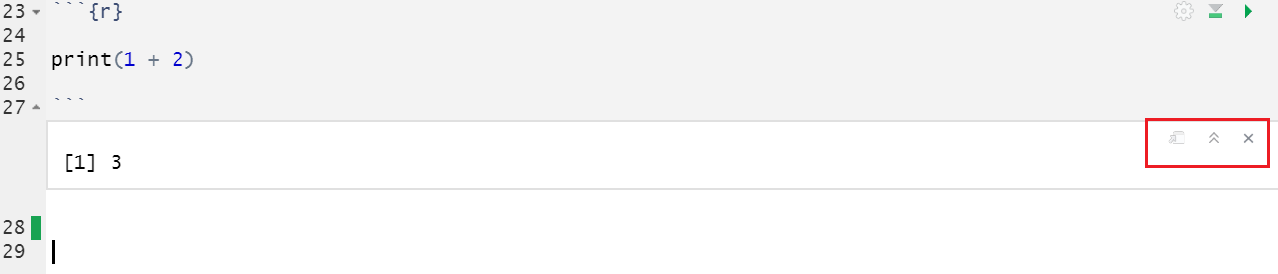
Perceba que um novo quadro aparece abaixo do trecho de código. Nas Figuras 52 A, 52 B e 52 C, você verá três ícones em vermelho com algumas opções, veja:
Figura 52 A: Ícone do chunk em uma nova janela.
![]() : abre o output em uma nova janela.
: abre o output em uma nova janela.
Figura 52 B: Ícone do chunk oculta os detalhes do quadro de output.
![]() : oculta
os detalhes do quadro de output.
: oculta
os detalhes do quadro de output.
Figura 52 C: Ícone do chunk fecha o quadro output.
![]() : fecha o
quadro output.
: fecha o
quadro output.
Por fim, o símbolo  executa todos os trechos de códigos anteriores ao chunk atual.
Esta função pode ser interessante caso você deseje iniciar a execução do
código a partir de um determinado ponto do documento, sem a necessidade
de rodar os trechos de códigos anteriores um a um. Você os rodará em
bloco.
executa todos os trechos de códigos anteriores ao chunk atual.
Esta função pode ser interessante caso você deseje iniciar a execução do
código a partir de um determinado ponto do documento, sem a necessidade
de rodar os trechos de códigos anteriores um a um. Você os rodará em
bloco.
5.1 Escrevendo os códigos de um relatório
Agora que entendemos como editar os chunks, vamos preparar
nosso relatório para gerar gráficos e tabelas a partir de códigos em
R. O primeiro passo é organizarmos o nosso ambiente de
análise nos seguintes passos:
- Carregar os pacotes que serão utilizados.
- Carregar as bases de dados.
- Armazenar os dados carregados em objetos que serão utilizados posteriormente.
Atenção
Lembre-se que você pode acessar a qualquer momento o curso “Análise de dados para a vigilância em saúde – curso básico” e o curso “Visualização de dados de interesse para a Vigilância em Saúde”, obtendo os códigos desejados para a confecção do seu relatório. Caso não tenha feito os cursos, sugerimos que se inscreva neles. Maiores informações em https://www.abrasco.org.br/site/analise-de-dados-para-a-vigilancia-em-saude/
Observe como você deverá preencher o chunk para executar o primeiro passo da nossa análise (carregar os pacotes que serão utilizados):
# Carregando os pacotes necessários
require(foreign)
require(tidyverse)
require(lubridate)
require(kableExtra)Vamos lá! Estamos construindo um relatório que irá apresentar a
situação da dengue em Rosas para o secretário de Estado. Para isso,
precisaremos utilizar dados de dengue para o Estado de Rosas. Aqui
iremos utilizar como base de dados o arquivo exportado do SINAN Net
chamado de NINDINET.dbf. Este arquivo está disponível no
menu lateral “Arquivos” do Ambiente Virtual do curso.
Também iremos filtrar os registros de agravos relacionados à dengue e, em seguida, criaremos algumas colunas com informações-chave sobre esse agravo (semana epidemiológica, mês, e ano da data de primeiros sintomas) desses registros. Todas estas rotinas (passos 2 e 3) serão acrescidas no primeiro passo da nossa análise. Veja os comandos abaixo:
# Carregando os pacotes necessários
require(foreign)
require(tidyverse)
require(lubridate)
require(kableExtra)
# Importando o banco de dados com a função `read.dbf()`
nindi <- read.dbf(file = 'Dados/NINDINET.dbf')
# Armazenando apenas dados para dengue
dengue <- nindi |>
# Filtrando apenas casos de dengue com a função filter()
filter(ID_AGRAVO == 'A90') |>
# Criando novas colunas com a função mutate()
# Convertendo a coluna DT_SIN_PRI (data de primeiros sintomas) para
# o formato de date (Date)
mutate(DT_SIN_PRI = ymd(DT_SIN_PRI),
# Criando nova coluna com a semana epidemiológica com o uso da função
# epiweek()
sem_epi = epiweek(DT_SIN_PRI),
# Criando nova coluna com o ano epidemiológico com o uso da função
# epiyear()
ano_epi = epiyear(DT_SIN_PRI),
# Criando nova coluna com o mês de primeiros sintomas
mes = month(DT_SIN_PRI))Agora replique estes códigos no chunk do seu
RStudio. Recomendamos que esta parte do código seja
inserida no primeiro trecho de código do seu arquivo .Rmd,
pois desta forma, todos os códigos executados posteriormente já contarão
com os pacotes e objetos necessários para as análises que faremos.
Lembre-se que você deverá sempre verificar se todos os pacotes
necessarios foram instalados instalados e carregados no R,
caso encontre algum aviso (warning) ou erro (error),
revise seu código e instale os pacotes necessários.

Muitas vezes os códigos que geram as tabelas e os objetos que serão
utilizados demoram um longo tempo para serem processados. Porém, com
experiência você aprenderá a fazer pequenos ajustes que tornarão o
processo mais rápido. A repetição de códigos, por exemplo, é um dos
grandes motivos que tornam o processamento de relatórios
.Rmd bastante demorados.
Uma alternativa que permite otimizar o tempo é fazer a preparação das
tabelas e dos objetos que serão utilizados nos relatórios automáticos em
outro arquivo de script em .R, de forma separada,
e salvá-los como objetos do tipo tabelas (.csv) ou em
objetos do tipo dados do R (.Rdata). Depois
basta mencionar esses objetos em seu arquivo .Rmd
utilizando a função source() no primeiro trecho de código
do seu relatório em RMarkdown. Assim, o R irá
buscar a versão “pronta” de sua tabela ou objeto, reduzindo o tempo de
produção do seu relatório.
Você terá como resultado um script mais sucinto e fácil de compreender por qualquer pessoa que o manusear.
Precisaremos agora configurar o chunk. Copie o trecho de
código que treinamos anteriormente e o insira trechos na linha 12 do seu
arquivo .Rmd. A linha 12 é a que contém o seguinte
código:
knitr::opts_chunk$set(echo = TRUE)Pronto, agora verifique se o seu arquivo .Rmd ficou
semelhante a Figura 53. Veja:
Figura 53: Contrução do chunk para o script de análise da dengue do Estado de Rosas.
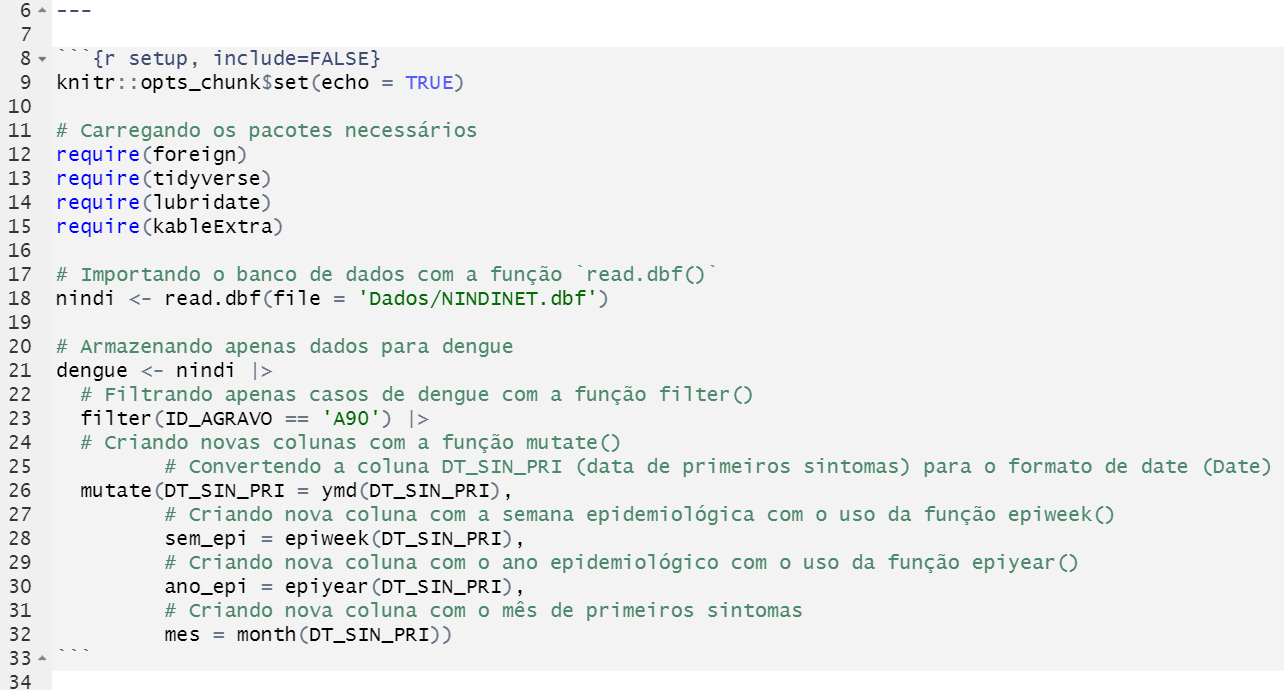
Note que na Figura 53 este trecho inicial de código possui o
argumento include=FALSE, ou seja, configuramos o
chunk para que o código seja executado apenas quando
renderizarmos o documento. Além disso, não deverá exibir nenhum
output.
Atenção
Caso tenha encontrado dificuldade de chegar a um arquivo com os scripts que utilizamos, não se preocupe e continue no curso!
Deixamos pronto para você um arquivo de estudo com todos os elementos
que aplicamos nesta subseção: o exemplo6.Rmd. Você poderá
encontrá-lo acessando o menu lateral “Arquivos” do Ambiente Virtual do
curso e fazer o download.