


6 Anonimização de dados
Até aqui você já aprendeu a realizar o cruzamento entre as base de dados de internados e de óbitos, avaliando através do linkage de bancos de dados se existe diferenças de registros entre os sistemas de informações ou não. Imagine agora que você necessitará enviar os dados para que alguns de seus colegas para o compartilhamento do que aconteceu para que houve divergencia entre os dados do SIM e do SIVEP-Gripe do Estado de Rosas.
Para isso você enviará uma tabela à seus colegas para elucidar os problemas com todos os registros linkados. Mas precisará utilizar alguma técnica que anonimize esses dados, mantendo-os de acordo com o que é solicitado pela Lei Geral de Proteção de Dados (LGPD). Ou seja, garantindo que os dados sensíveis referentes aos óbitos de Rosas não sejam revelados. Para esta situação a forma mais adequada será utilizar a anonimização dos dados.
Vamos lá!

Segundo a Lei Geral de Proteção de Dados Pessoais (LGPD ou LGPDP):
Pseudo-anonimização é “o tratamento por meio do qual um dado perde a possibilidade de associação, direta ou indireta, a um indivíduo, senão pelo uso de informação adicional mantida separadamente pelo controlador em ambiente controlado e seguro”.
Anonimização é a “utilização de meios técnicos razoáveis e disponíveis no momento do tratamento, por meio dos quais um dado perde a possibilidade de associação, direta ou indireta, a um indivíduo;” e o dado anonimizado como “dado relativo a titular que não possa ser identificado, considerando a utilização de meios técnicos razoáveis e disponíveis na ocasião de seu tratamento”.
Dado pessoal é a “informação relacionada a pessoa natural identificada ou identificável”, como nome completo, e-mail, telefone, idade, estado civil, localização e endereço.
Dado sensível é o “dado pessoal sobre origem racial ou étnica, convicção religiosa, opinião política, filiação a sindicato ou a organização de caráter religioso, filosófico ou político, dado referente à saúde ou à vida sexual, dado genético ou biométrico, quando vinculado a uma pessoa natural”.
Para saber mais acesse a LGPD na integra clicando aqui
Uma das possíveis técnicas que pode ser empregada para anonimização é o uso de um valor hash para cada registro. Valores hash são obtidos por funções que utilizam diversos tipos de algoritmos para calcular uma sequência de valores codificados no formato hexadecimal que sumarizam uma informação retornando um código de tamanho fixo. Essas funções são empregadas em criptografia, como chaves que “autenticam” um arquivo, e-mail, etc. Qualquer pequena alteração nos dados gera um hash completamente diferente.
Acompanhe o script a seguir e replique-o em seu
RStudio:
# Carregando o pacote digest
library(digest)
# Gerando uma chave anonimizada com a função digest()
digest('Maria da Silva Lemos')#> [1] "430498451f4257b9599844c277da43ae"# Gerando uma chave anonimizada com a função digest()
digest('Maria de Silva Lemos')#> [1] "7241c03f2bab6c64967c960ed603e9e0"Note que a mudança de apenas uma letra (e para
a) gera um código hash completamente diferente.
Veja como podemos gerar uma “chave” concatenando diversos campos, no
caso, nome, sexo, idade, data de nascimento e nome da mãe, separando
cada campo com duas barras (\\) e gerando um hash dessa
chave! Acompanhe o script a seguir e replique-o em seu
RStudio:
digest('Kauan Azevedo Azevedo//masculino//1965-07-27//Analia Azevedo Azevedo')#> [1] "f25a02e3951af974d6e3e47b0eb0e8cd"Acompanhe o script a seguir e replique-o em seu
RStudio:
# Criando um objeto com um novo hash de anonimização denominado sivep_dup_hash
sivep_dup_hash <- sivep_dedup |>
# com uso da função mutate()
mutate(
# Criando uma variável para a chave
chave = paste(nome, sexo, data_nasc, nome_mae, sep = '//'),
# Criando uma nova hash a partir da chave criada com uso das
# funções map_chr() e digest()
hash = map_chr(.x = chave, .f = function(x) {digest(x, algo = 'md5')})
)
sivep_dup_hash |>
# Selecionando as variáveis de interesse com o uso da função select()
select(nu_notific, chave, hash) |>
# Selecionando apenas as linhas iniciais da tabela com a função head()
head() |>
# Visualizando a tabela resultante com o uso da função kable()
kable()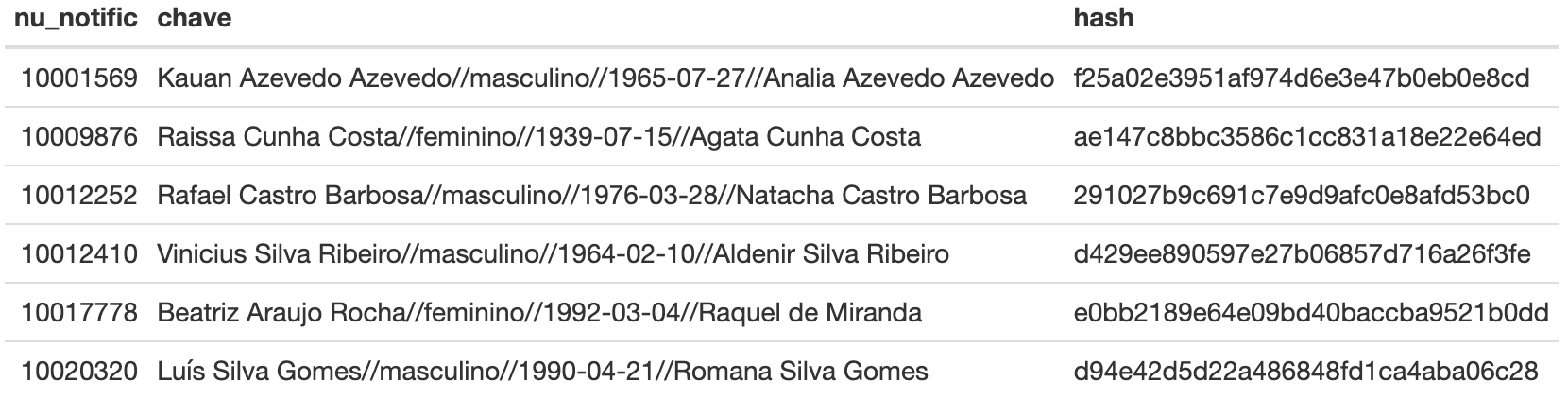
Vamos aplicar essa chave para cada um dos campos do banco SIVEP-Gripe depuplicado (sivep_dedup) e, por fim, vamos exibir os campos “número da notificação”, “chave” e o “hash”.
Note que não usamos o número do CPF para fazer o hash. Agora
vamos agrupar por hash e pedir para verificar todos o
hashs que aparecem mais de uma vez! Acompanhe o script
a seguir e replique-o em seu RStudio:
sivep_dup_hash |>
# Remove a variável "chave" com a função select()
select(-chave) |>
# Agrupa os registros com a função group_by()
group_by(hash) |>
# Subagrupando a tabela de valores com mesma hash e salvando-os como uma
# lista em cada linha
nest() |>
# Cria a variável "pares" com o número de registros por hash com o uso da
# função map_chr(), nrow() e mutate()
mutate(pares = map_chr(data,nrow)) |>
# Filtra os valores com mais de um registro com uso da função filter()
filter(pares > 1) |>
# Desagrupando os valores da lista presentes na "coluna" data
unnest(data) #> # A tibble: 8 × 9
#> # Groups: hash [4]
#> hash nu_no…¹ nome sexo data_nasc idade cpf nome_…² pares
#> <chr> <dbl> <chr> <chr> <date> <dbl> <chr> <chr> <chr>
#> 1 2599f4d458a9bf8d6a8e… 1.59e7 Rafa… masc… 1989-01-23 33 495.… Edlain… 2
#> 2 2599f4d458a9bf8d6a8e… 1.60e7 Rafa… masc… 1989-01-23 33 <NA> Edlain… 2
#> 3 5729ec3fc10a3c9eb77d… 1.72e7 Math… masc… 1967-04-08 55 <NA> Darlen… 2
#> 4 5729ec3fc10a3c9eb77d… 7.08e7 Math… masc… 1967-04-08 55 194.… Darlen… 2
#> 5 8c6d7a54bc45dc4eadcb… 2.03e7 Doug… masc… 1961-12-05 60 <NA> Iza Pi… 2
#> 6 8c6d7a54bc45dc4eadcb… 7.95e7 Doug… masc… 1961-12-05 60 921.… Iza Pi… 2
#> 7 63671534dc924a23d86f… 3.24e7 Bren… masc… 1969-03-11 53 555.… Lindom… 2
#> 8 63671534dc924a23d86f… 6.05e7 Bren… masc… 1969-03-11 53 <NA> Lindom… 2
#> # … with abbreviated variable names ¹nu_notific, ²nome_maeComo não usamos o número do CPF esse método também funciona como um
linkage determinístico mostrando alguns pares adicionais que
não foram pegos na deduplicação. A existência de CPF com NA
piora a qualidade do linkage, especialmente porque não se pode
gera uma comparação neste caso.

Algo que é bastante importante no uso das hashs para anonimização de dados, é que a qualquer momento você poderá utilizar a hash para retornar o registro original, ou seja, caso você deseje encontrar a qual indivíduo se refere a hash você conseguirá consultar novamente a tabela que gerou os hash e obter o banco identificado para recompor a informação.