


3 Tipos de linkage
Vimos até aqui que parear bases de dados parece ser desafiador no dia
a dia e o R te apoiará na construção de rotinas de
linkage de dados. É desafiador se deparar com a ausência do
campo identificador unívoco nas bases de dados da saúde, o que impede a
identificação direta de registros de um mesmo indivíduo em bases de
dados distintas ou mesmo não conseguir resultados exatos quando
relacionamos identificadores únicos. Acompanhe nas subseções a seguir os
métodos de relacionamentos probabilístico, determinístico ou híbridos e
aprenda a escolher a técnica adequada para a análise que deseja fazer,
aplicando algoritmos de encadeamento mais sofisticados que se baseiam na
combinação de variáveis de identificação. Vamos lá!
3.1 Linkage determinístico
Linkage determinístico é o relacionamento que ocorre quando o pareamento é feito pela correspondência exata entre registros de dois bancos de dados. Este pareamento pode ocorrer em apenas um campo que possua um identificador único para indivíduo. Por exemplo, quando utilizamos identificadores como o Cadastro de Pessoas Físicas (CPF), o número do Registro Geral (RG) ou do Cartão Nacional de Saúde (CNS). Outra possibilidade é quando ocorre a combinação de um ou mais campos presentes nos dois bancos (por exemplo primeiro nome + sobrenome + data de nascimento).
Em bancos de dados com identificadores únicos (como CPF) os métodos de linkage determinísticos são bastante eficientes em encontrar correspondências verdadeiras, enquanto discriminam sempre que existir quaisquer inconsistências entre as informações presentes nesses bancos.
Note que estas comparações partem do pressuposto de que os dados são 100% fidedignos, isto é, sem erros de digitação, abreviações, valores faltantes ou qualquer outra imprecisão entre cada par de registros.
Caso seja necessário realizar uma comparação entre registros em que seja incorporada a possibilidade de pequenas inconsistências entre os bancos, pode ser interessante utilizar abordagens mais flexíveis, como o linkage probabilístico.
Veremos como aplicar na prática a seguir.
3.2 Linkage probabilístico
O linkage probabilístico é uma forma de análise de correspondência entre registros que permite comparar dados a partir de scores ou índices que considerem a probabilidade de dois registros pertencerem a um mesmo indivíduo. Estas comparações utilizam métricas que atribuem pesos diferentes para a concordância e discordância entre estes registros. Parece complicado? Acompanhe este exemplo:
Considere que você possui duas bases de dados (hipotéticas) com registros de casos de dengue. Nessas bases você identifica registros que podem ser de um mesmo individuo:
- Na primeira base de dados possui um sr. “Fabio Luiz Rosa”, e
- Na segunda base de dados possui um sr. “Fábio Luis da Rosa”.
Em uma comparação determinística, os dois registros seriam considerados não-correspondentes, pois apresentam discordâncias entre si: um deles possui a ausência de acento, a última letra do segundo nome é diferente, e apenas um deles apresenta preposição antes do último nome.
Observe na Tabela 4 outros exemplos que comparam divergências comuns entre palavras inconsistentes.
Tabela 4: Exemplos de incosistências comuns encontradas na variável nome.
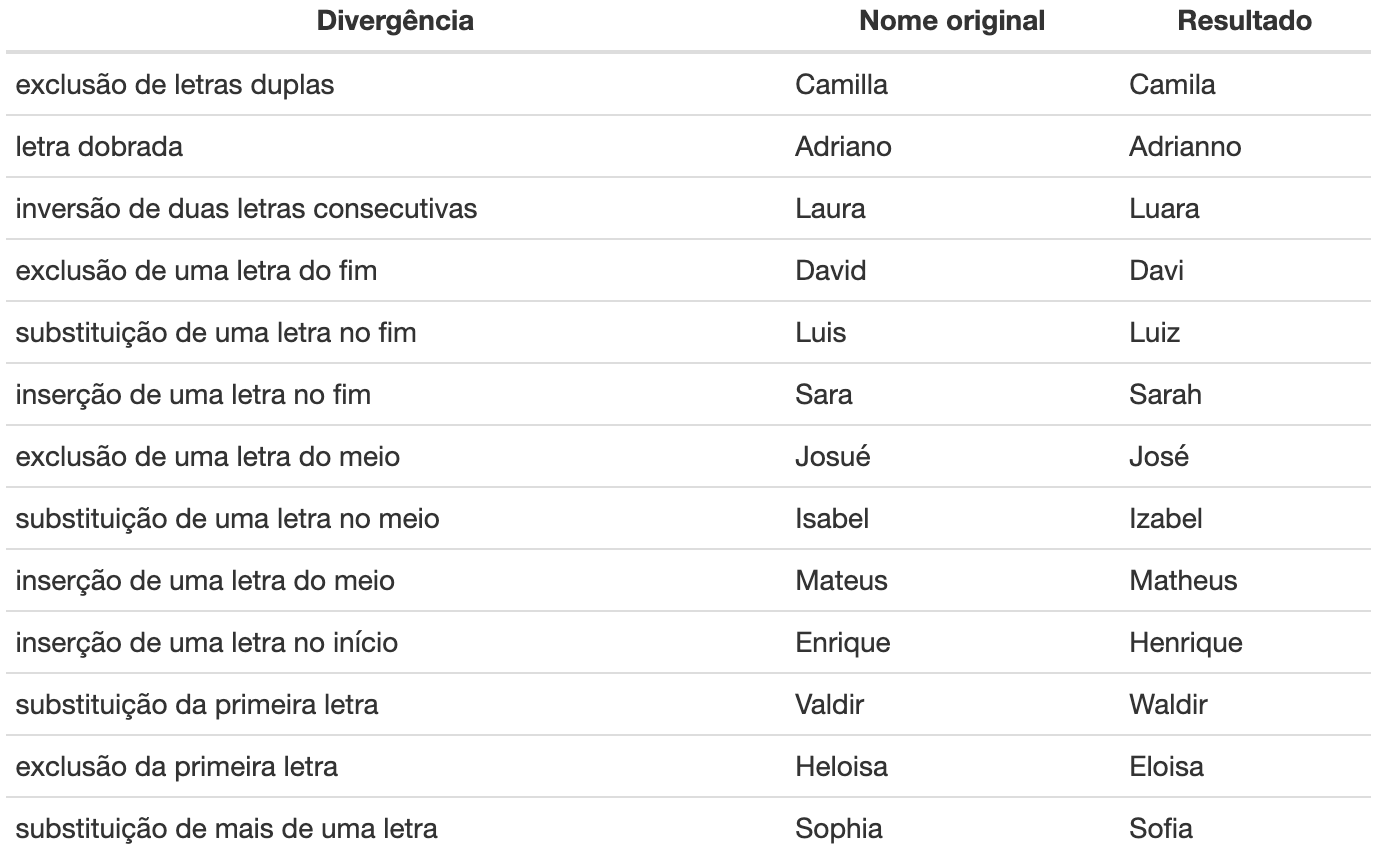
Não é apenas em textos ou nomes, as inconsistências também podem ocorrer em dados com valores numéricos (substituição de caracteres em CPFs, RGs e CNSs) ou até mesmo em datas (mudança na ordem entre mês e dia, digitação incorreta de um ou mais valor da data).
Já em uma comparação probabilística, um índice seria atribuído à essas correspondências, indicando uma alta probabilidade de se referirem à mesma pessoa. Observe a seguir o detalhamento de duas das métricas comumente empregadas em comparações probabilísticas: a distância de Hamming e a distância de Levenshtein
Algoritmos baseados em distancia
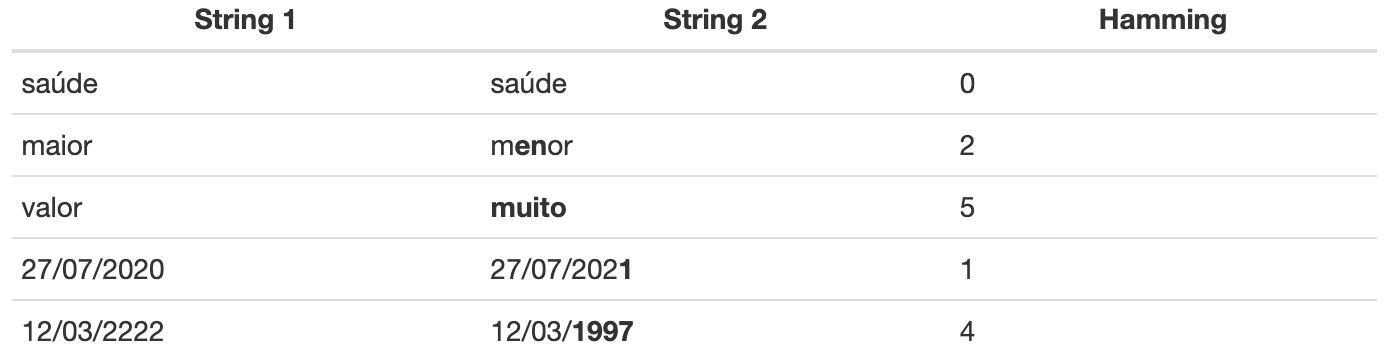
- A distância de Hamming
Este índice compara duas sequências de caracteres de mesmo comprimento e calcula o número de elementos que diferem entre si. Em outras palavras, ela mede o menor número de substituições necessárias para transformar uma sequência de caracteres em outra.
Veja alguns exemplos na Tabela 5 a seguir. Nela, os caracteres substituídos estão marcados em negrito.
Tabela 5: Exemplos de correspondências no linkage probabilístico utilizando a distância de Hamming.
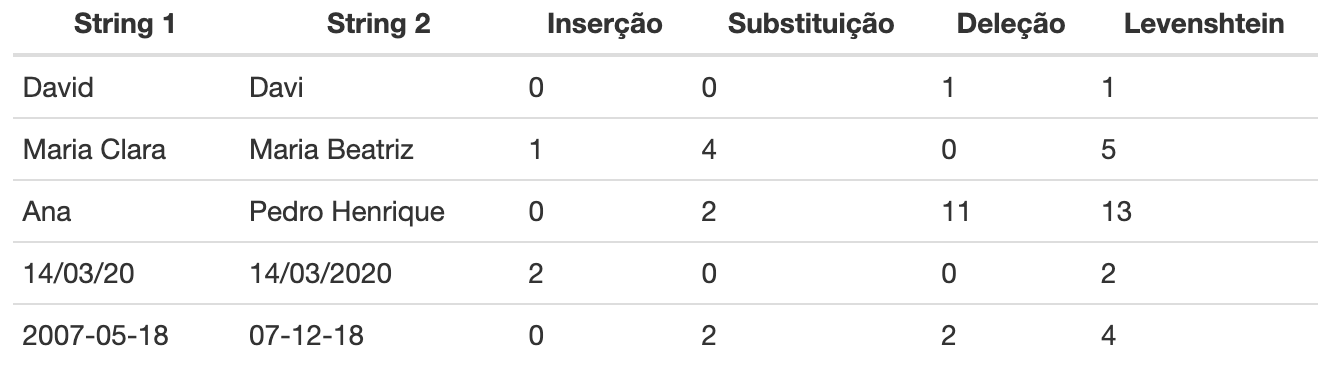
A distância de Levenshtein
Este índice é uma forma mais ampla da distância de Hamming e permite comparar sequências de caracteres de diferentes tamanhos. Além de substituições, outras “transformações” incluem a inserção ou exclusão de caracteres.
Veja estes exemplos na Tabela 6 a seguir:
Tabela 6: Exemplos de correspondências no linkage probabilístico utilizando a distância de Levenshtein.
- A similaridade de Jaro Winkler
A similaridade de Jaro-Winkler é uma maneira de medir o quão semelhantes são estas duas strings. O valor de similaridade de Jaro-Winkler varia de 0 a 1. Onde 1 significa que as strings são exatamente iguais e 0 significa que não há semelhança nenhuma entre as duas strings.
Quando se compara duas strings este método leva em conta o tamanho de cada string, o número de caracteres em comum, o número de transposições . Ou seja , troca de letras. Este método é uma maneira mais complexa de calcular a similaridade do que as distâncias de Hamming e Levenshtein . Veja o exemplo a seguir:
Extemplo 1: String 1 = “Joana Maria da Silva” String 2 = “Joanna Maia da Sylva”
Exemplo 2: data 1 = “11/12/1987” data 2 = “12/11/1987”

* Hamming só pode ser usado para comparar strings do mesmo tamanho.
Como podemos ver a similaridade de Jaro-Winkler foi superior as duas outras distâncias e apontou similaridade mais altas nos dois exemplos.
3.3 Linkage híbrido
Já o linkage híbrido é uma combinação entre os métodos determinísticos e probabilísticos de linkage. Utilizando o método híbrido podemos utilizar os pontos positivos de cada abordagem, acelerando a velocidade de processamento e aumentando a probabilidade de que correspondências e não-correspondências sejam identificadas de forma correta.
Uma exemplificação desta abordagem pode ser feita ao se considerar o seguinte cenário: considere um banco de prontuários de hospitais contendo CPF e NOME COMPLETO de todos os pacientes. Sua diretora pediu para que você trazer uma tabela com os dados de prontuário de alguns pacientes que foram a óbito. Para isso, você necessitará parear as informações de prontuários com o banco de dados de mortalidade (SIM) do município.
Ao iniciar a avaliação dos bancos de dados que fará o linkage você percebeu que os dados dos prontuários possuem apenas 55% de seus registros com CPF preenchido. Assim, você precisará utilizar outras variáveis para concluir o linkage. Vamos lá! Você fará em duas etapas:
- Na primeira etapa, fará a correspondência entre os registros comparando-se apenas entre os registros de prontuários que possuem o número do CPF preenchido.
- Após você fará uma segunda análise, comparando os registros faltantes pelos nomes completos registrados em cada banco.
Misturando métodos, você obterá um resultado com uma acurácia mais alta, garantindo a qualidade adequada para suas análises.