


5. Criação de mapas temáticos
Mapas temáticos são aqueles destinados a representar quaisquer fenômenos distribuídos geograficamente, indo além da representação ou visualização do espaço em si. A representação temática busca explorar, analisar e sintetizar dados sobre um determinado assunto e, por vezes, correlacionar com outros tipos de dados. Dessa forma, utilizam-se dados gráficos e não gráficos já existentes para compor uma análise. Eles são muito utilizados nas pesquisas socioeconômicas, de saúde e ambientais.
Atualmente, com as ferramentas de análise espacial disponíveis, o mapa não é somente um produto para comunicar algo. Pelo contrário, uma representação adequada é o começo de todo processo de análise. Para a Vigilância em Saúde isso é muito poderoso, pois utilizar mapas para abordar temas de interesse, cruzando informações e analisando correlações torna-se uma das habilidades mais importantes para a saúde pública.
Nesse tópico, vamos abordar a elaboração de alguns dos principais mapas para a Vigilância em Saúde e vamos utilizar os arquivos vetoriais que já importamos e mais algumas bases de dados necessárias para cálculo de algum indicador.
Vamos lá?
5.1 Mapa base
O mapa base é o primeiro elemento a ser adicionado na composição de um mapa. Também é chamado de mapa de fundo, e em inglês basemap e backgroundmap.
É o mapa que representará a área geográfica de estudo ou os limites administrativos necessários para representar o fenômeno de interesse. Por vezes, é substituído por outra camada, principalmente nos mapas temáticos que utilizam toda a área para representar um fenômeno.
Como qualquer elemento adicionado durante a composição de um mapa, a escolha do mapa base deve seguir critérios que sempre melhorem a interpretação e ajudem ao leitor do mapa a entender o que está sendo representado. Um mapa base pode ser desde a representação dos limites administrativos a imagens do terreno estudado.
Figura 10: Exemplos de mapas base utilizados para mapas temáticos.
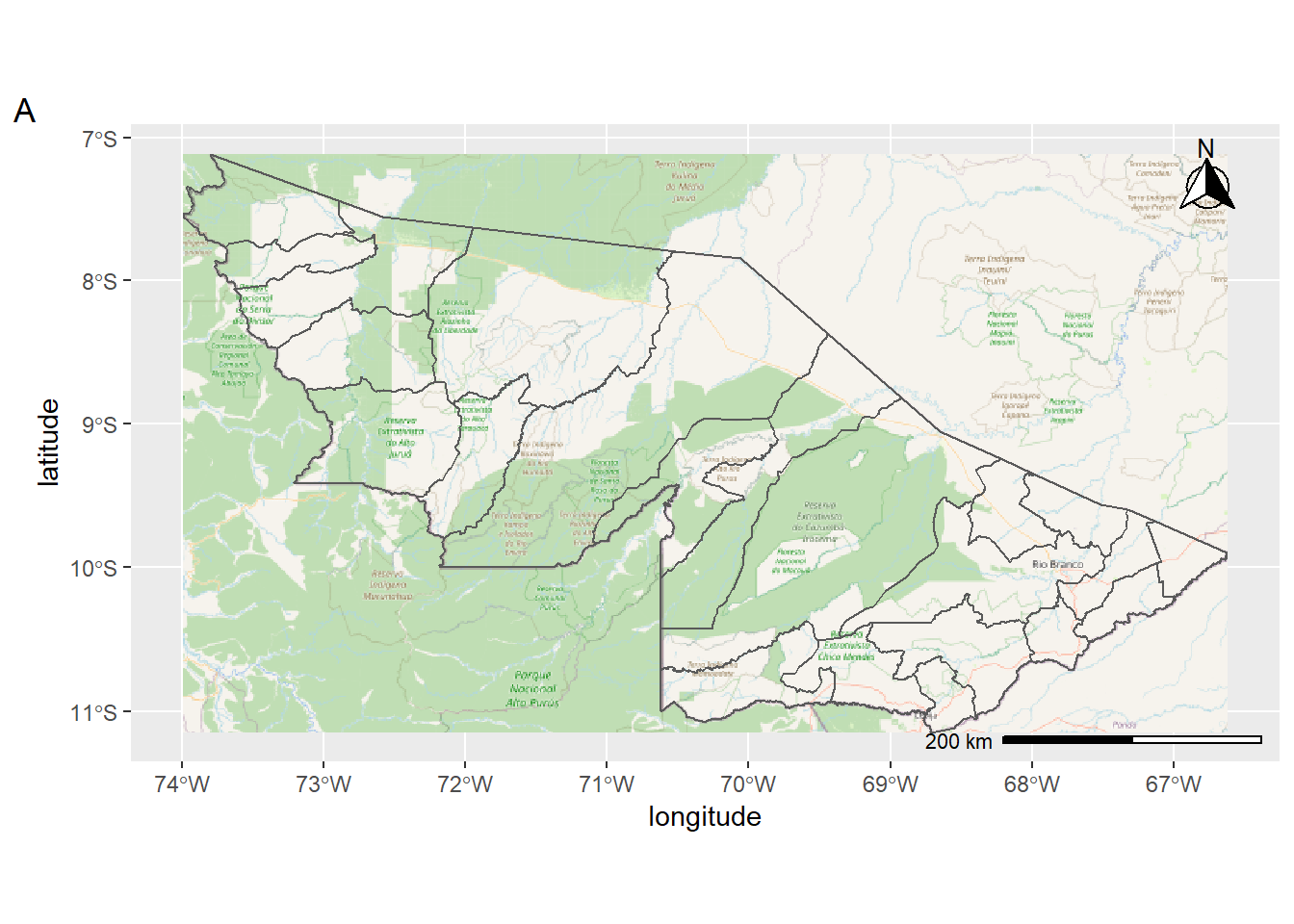
A depender do objetivo, os mapas base podem conter diferentes informações. Neste curso, utilizaremos o mapa base que representa os municípios do Estado do Acre. Dessa forma, vamos destacar as informações que vamos sobrepor. Acompanhe os demais tipos de mapas utilizados na Vigilância em Saúde.
5.2 Mapa de símbolos proporcionais
Mapas de símbolos proporcionais representam a ocorrência de um evento em valores absolutos por meio da variação proporcional do tamanho de uma figura geométrica, geralmente círculo, sobrepostos sobre a unidade territorial. O círculo é localizado conforme a posição real do evento ou atribuído à localização de referência, como o centro geográfico (centróide) de um município ou de um bairro.
A representação de números totais por meio da variação do tamanho respeita a ideia de quão maior é um valor em relação a outro, sem envolver relações geográficas. Além disso, permite uma leitura fácil para entender as diferenças entre as unidades territoriais avaliadas. Mas, uma atenção especial deve ser dada à legenda, pois a interpretação deve ser clara. Ou seja, os símbolos proporcionais devem se destacar de forma única.
Para demonstrar este mapa, vamos utilizar os dados de população do estado do Acre, segundo os municípios. Nós utilizamos estes dados no curso básico “Análise de dados para a Vigilância em Saúde” e retornaremos a eles aqui. Primeiro, importaremos os dados, em seguida vamos uni-los à base geográfica utilizando o geocódigo do município (o código do IBGE) e, finalmente, vamos plotar o mapa.
A nossa base de população contém dados do estado do Acre de 2009 a
2021. Ao importá-la, perceba que o comando possui um argumento chamado
col_types. Esse argumento é necessário para garantir que a
primeira coluna do arquivo, chamada “Codigo”, se mantenha como o formato
original “character”.
Além disso, vamos padronizar o nome das colunas (minúsculas, sem
acento, sem espaço e sem colunas começando com números) utilizando a
função clean_names() do pacote janitor
(perceba que após corrigir o nome das colunas, aquelas que iniciavam com
números, possuem a letra “x” no lugar). Execute o código:
# Carregando tabela com dados de população do acre para o objeto pop_ac
# utilizando a função read_csv2()
pop_ac <- read_csv2('Dados/pop_ac_09_21.csv', col_types = list("character"))#> ℹ Using "','" as decimal and "'.'" as grouping mark. Use `read_delim()` for more
control.# Padronizando o nome das colunas utilizando a função `clean_names()`
# do pacote janitor
pop_ac <- clean_names(pop_ac)Agora, vamos unir à base geográfica de municípios que será, nesse
caso, nosso mapa base. Para isso, vamos utilizar a função
left_join() do pacote dplyr. Como o geocódigo
possui nomes diferentes em cada base, vamos indicar no argumento
by quais colunas serão utilizadas como chave.
# Unindo a tabela ac_municipios_5880 com pop_ac com a função left_join()
pop_geo_ac <- ac_municipios_5880 |>
# A ligação é feita pela correspondência entre as colunas "cod_mun" e "codigo"
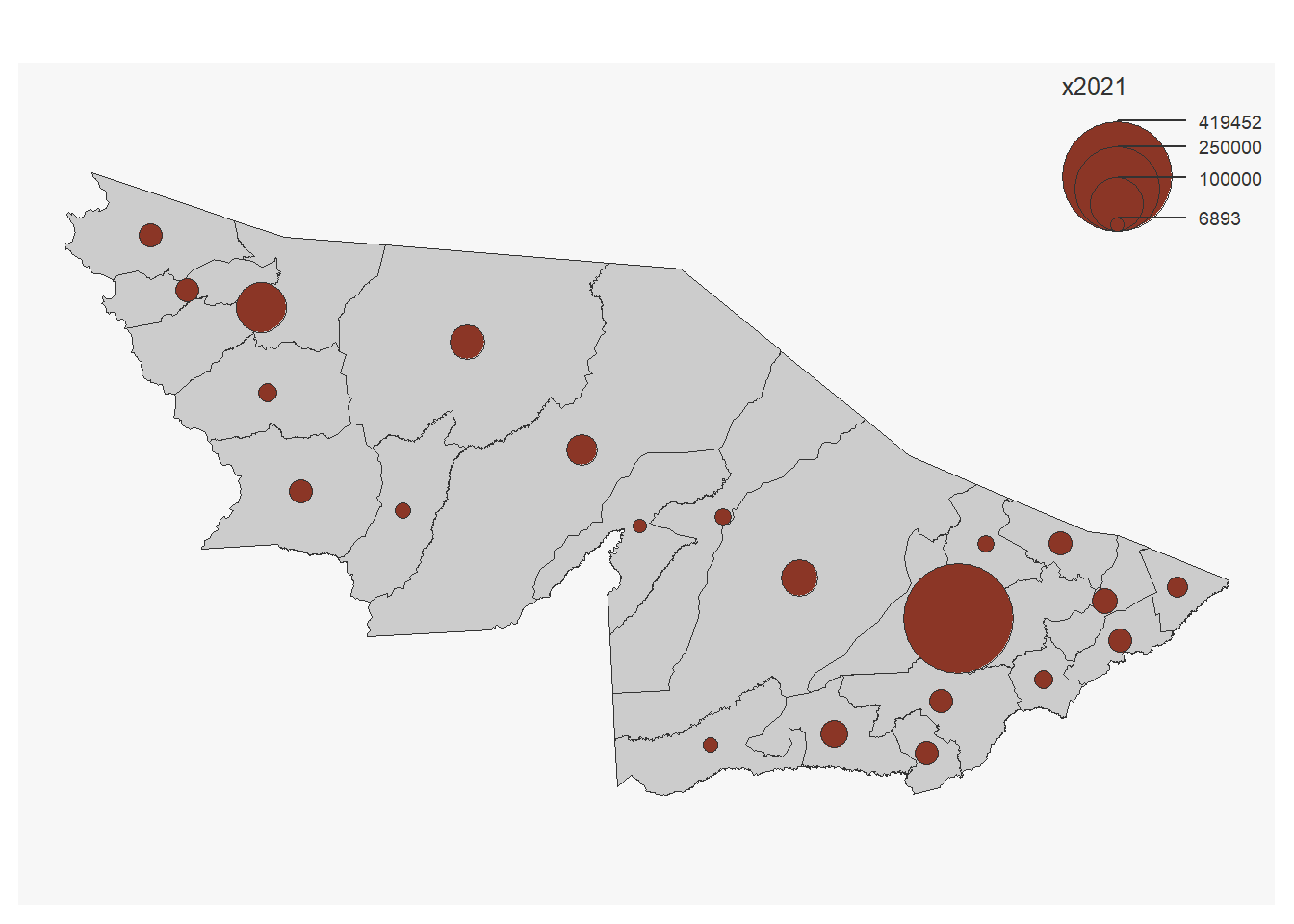
left_join(pop_ac, by = c('cod_mun' = 'codigo')) Por último, vamos plotar o mapa utilizando a coluna da população de
2021 (“x2021”) no argumento var. Note que ao utilizar o
pacote mapsf temos uma redução da necessidade de várias
linhas de comandos. A função mf_prop() já calcula o tamanho
dos círculos, classifica e posiciona a legenda.
# Plotando o objeto pop_geo_ac com uso da função mf_map()
mf_map(pop_geo_ac) |>
# Indicando o tamanho proporcional da população com uso da função mf_prop()
mf_prop(var = "x2021")Figura 11: Exemplo de Mapa de símbolos proporcionais.
Viu como é fácil? Apesar de poucas linhas, podemos adicionar mais complexidade, deixando o mapa com uma melhor qualidade do mapa, como adicionar os elementos cartográficos e estilizar um pouco mais. Faremos esse processo por etapas:
- Primeiro, vamos utilizar a função
mf_theme()que apresenta vários argumentos para criar um tema para o mapa. Neste caso vamos apenas alterar a cor do fundo para branco utilizando o argumentobg. Esse fundo não é o fundo do mapa, mas a área por trás do mapa.
# Definindo a cor de fundo por trás do mapa como "branco",
# com uso da função mf_theme()
mf_theme(bg = "white")- Em seguida, vamos adicionar o mapa base com os limites dos
municípios. Vamos utilizar o argumento
colpara alterar a cor do preenchimento da área dos municípios. Perceba que usamos a codificação de cores (hexadecimal) apresentada no curso. Vamos também sobrepor a camada com os círculos proporcionais, indicando os seguintes argumentos:
var: coluna com os dados a serem plotados;leg_pos: posição da legenda. Este argumento aceita as seguintes instruções:- topright : acima à direita;
- topleft: acima à esquerda;
- bottomright: abaixo à direita;
- bottomleft: abaixo à esquerda.
leg_title: o título da legenda;col: este argumento dentro da funçãomf_prop()se refere à cor interna dos círculos.
# Plotando o objeto pop_geo_ac com uso da função mf_map()
# O argumento "col" define a cor de preenchimento utilizando o código de
# cor hexadecimal
mf_map(pop_geo_ac, col = "#FAFAFA") |>
# Indicando o tamanho proporcional da população com uso da função mf_prop()
mf_prop(
# Definindo a variável x2021 para cálculo do tamanho proporcional dos círculos
var = "x2021",
# Definindo a posição da legenda para "abaixo e à esquerda"
leg_pos = "bottomleft",
# Definindo o título do gráfico
leg_title = "Populacao Acre 2021",
# O argumento "col" define a cor de preenchimentto dos círculos utilizando
# o código de cor hexadecimal
col = "#FFAD48"
)- Agora vamos inserir a seta de norte utilizando a função
mf_arrow(). Essa função tem como principal argumento a posição da seta, indicada porpos. Note abaixo que indicar a posição é similar às configurações citadas acima.
# Definindo a posição da seta de norte para a região "superior e à direita"
# com a função mf_arrows()
mf_arrow(pos = "topright")- Por fim, vamos inserir a escala, utilizando a função
mf_scale(). O tamanho da escala é padronizado, mas é possível alterá-lo utilizando o argumentosize. Mas cuidado, este argumento é legível quando está sendo utilizada um sistema de coordenada plana.
# Inserindo a escala com a função mf_scale()
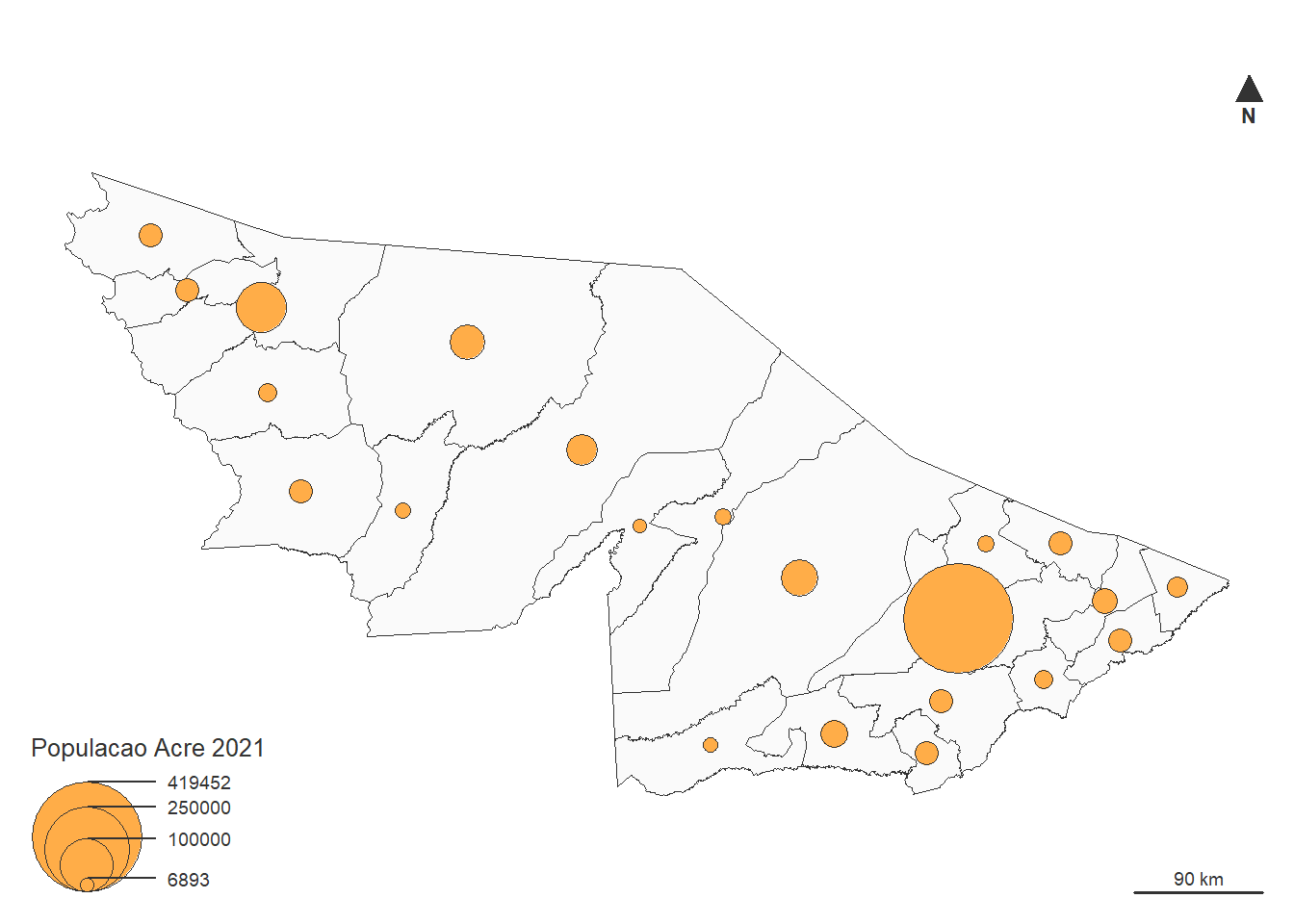
mf_scale()Abaixo, apresentamos o código completo. Execute-o e observe o mapa gerado:
# Definindo a cor de fundo por trás do mapa como "branco", com uso da
# função mf_theme()
mf_theme(bg = "white")
# Plotando o objeto pop_geo_ac com uso da função mf_map()
# O argumento "col" define a cor de preenchimento utilizando o código de
# cor hexadecimal
mf_map(pop_geo_ac, col = "#FAFAFA") |>
# Indicando o tamanho proporcional da população com uso da função mf_prop()
mf_prop(
# Definindo a variável x2021 para cálculo do tamanho proporcional dos círculos
var = "x2021",
# Definindo a posição da legenda para "abaixo e à esquerda"
leg_pos = "bottomleft",
# Definindo o título do gráfico
leg_title = "Populacao Acre 2021",
# O argumento "col" define a cor de preenchimentto dos círculos utilizando
# o código de cor hexadecimal
col = "#FFAD48"
)
# Definindo a posição da seta de norte para a região "superior e à direita"
# com a função mf_arrows()
mf_arrow(pos = "topright")
# Inserindo a escala com a função mf_scale()
mf_scale()Figura 12: Exemplo de elaboração de mapas com símbolos proporcionais.

Note que não utilizamos o operador pipe em todas as situações. Para
sobreposição de elementos cartográficos, como seta de norte, escala ou
até mesmo alterações do layout, o pacote mapsf não
exige o uso do pipe em todas as situações.
Utilizando o pacote mapsf também é possível inserir
título e notas de rodapé, utilizando as funções mf_title()
e mf_credits(). O uso dessas funções é muito similar às
demais do pacote.
mf_theme(bg = "white")
mf_map(pop_geo_ac, col = "#FAFAFA") |>
mf_prop(
var = "x2021",
leg_pos = "bottomleft1",
leg_title = "Populacao Acre 2021",
col = "#FFAD48"
)
mf_arrow(pos = "topright")
mf_scale(pos = "bottomright")
mf_title(txt = "Distribuicao espacial da populacao do Estado do Acre segundo
municipio, 2021.", cex = .8)
mf_credits(txt = "Fonte: IBGE-2021.", pos = "bottomleft")Figura 13: Exemplo de elaboração de mapas com símbolos proporcionais com layout completo.
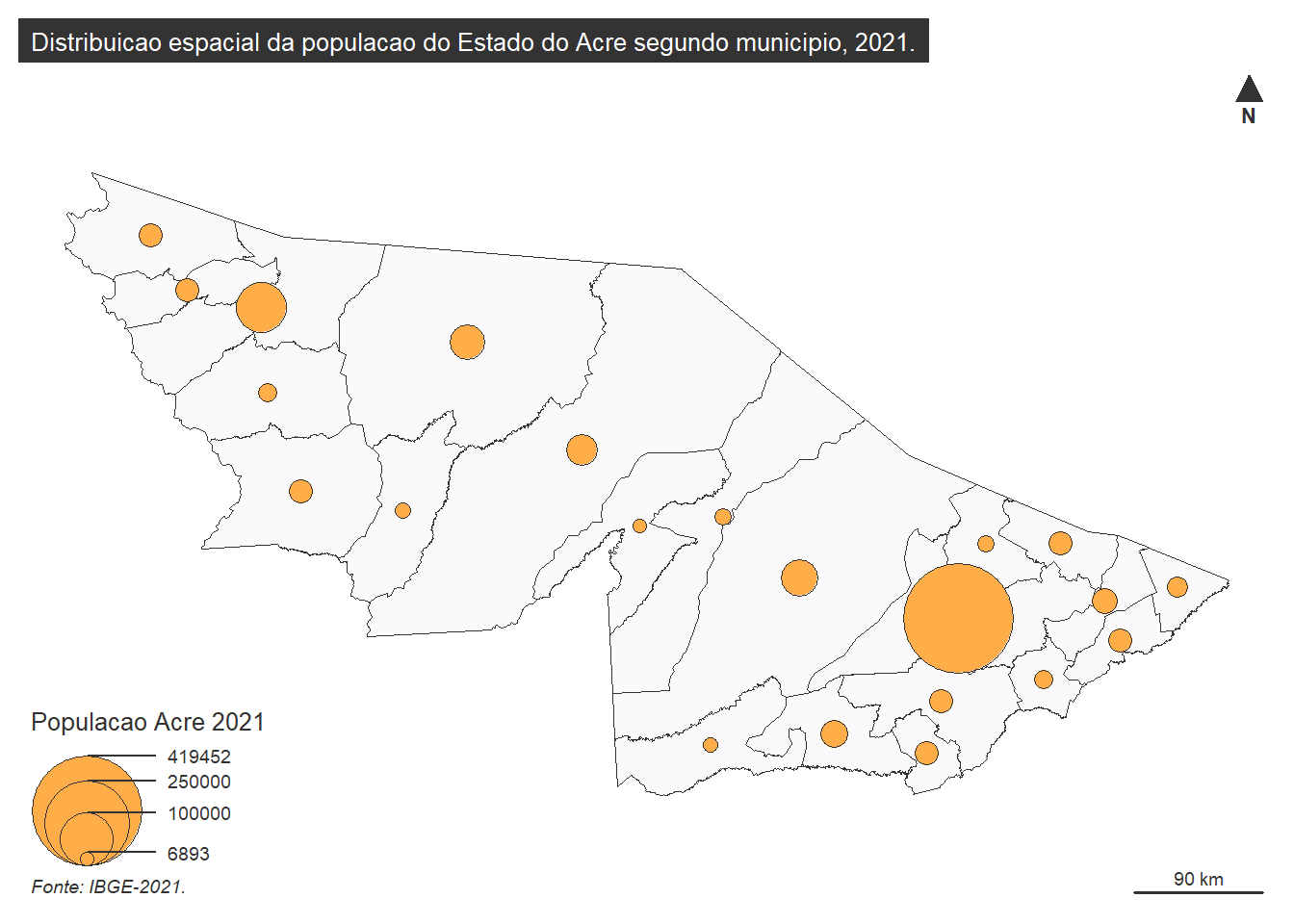
A população total do Acre estava em cerca de 900 mil habitantes em 2021. Analisando a distribuição da população, podemos notar que a população acreana está irregularmente distribuída, com uma grande concentração na capital Rio Branco. A ligação entre a região norte e noroeste do estado se dá, principalmente, pela Rodovia BR-364. Possivelmente, há uma relação entre as regiões mais povoadas, as redes de transporte (seja rodoviária, seja hidroviária) e a extensão da Floresta Amazônica.
Essa distribuição irregular pode gerar uma desigualdade na área da saúde, com concentração da infraestrutura de saúde como referência hospitalares e equipamentos de diagnósticos. Como analista da Vigilância em Saúde, estas informações podem ser ampliadas, integradas com as realidades locais, acrescidas de detalhes sobre o diagnóstico situacional e potencializadas com o uso de indicadores de saúde.
Agora, vamos conhecer o principal mapa utilizado na Vigilância em Saúde.
5.3 Mapa coroplético
Mapas coropléticos representam dados de unidades de áreas delimitadas, que podem ser bairro, áreas administrativas, distritos ou até mesmo o município. Cada área recebe uma cor de acordo com a classificação prévia dos dados, que podem ser taxas de incidências, razões de mortalidade, entre outros. Para elaborá-lo, basta que haja as taxas para cada área de análise e o arquivo vetorial com os limites administrativos.
São muito utilizados para análise do comportamento de uma doença em relação ao tempo ou para comparação entre áreas. Sua escolha se dá, muitas vezes, devido aos dados da vigilância serem divulgados por área (bairros, regiões). Além disso, como não apresenta a localização exata do fenômeno, a privacidade é mantida.
Quando utilizado para comparar comportamento de um evento entre semana epidemiológicas, meses ou anos, é necessário que a classificação dos dados deve ser a mesma para permitir uma comparação adequada.
Os valores absolutos ou totais não são adequados para representar eventos relacionados à saúde utilizando mapas coropléticos e não devem ser usados quando se referir a eventos que podem ser influenciados pelo tamanho da população em risco ou pelo tamanho da área que se origina os casos. Por exemplo, utilizar mapa coroplético para mostrar onde há mais casos de uma doença não é adequado, considerando que há uma possibilidade alta de onde tiver mais habitante, ter mais casos. Por isso, a indicação é pela adoção do uso de indicadores como taxas de incidência ou prevalência.
A composição deste tipo de mapa envolve, basicamente, quatro etapas essenciais:
- definição da área que será representada;
- cálculo das razões, frequências ou taxas da variável de interesse;
- classificação da variável;
- visualização do mapa.
Vamos praticar estas etapas com dois exemplos que seguem nos próximos tópicos.
5.3.1 Prevalência de Hanseníase no Acre
Para demonstrar a elaboração do mapa coroplético, nossa área de interesse continuará no Estado do Acre. Vamos utilizar os dados da prevalência de hanseníase entre os municípios do Acre, os quais foram detalhados na Unidade 5 do curso básico “Análise de dados para a Vigilância em Saúde”. Abaixo, vamos resgatar a linha de cálculo da prevalência, revisando os passos utilizados. Para mais detalhes, recomendados fortemente a realização do curso.
A prevalência de hanseníase estima a magnitude da endemia no Acre. Ela deve ser estudada com base na totalidade de casos em tratamento no momento da realização desta avaliação. Uma alta prevalência (valores acima de 5 casos por 10 mil habitantes) pode indicar um cenário de baixo desenvolvimento socioeconômico e falta de ações efetivas do município para o controle da doença. Por outro lado, a baixa prevalência (valores menores que 1 caso por 10 mil habitantes) pode indicar que a hanseníase não deve considerada um problema de saúde pública.
No código abaixo vamos importar os casos de hanseníase do SINAN no
ano de 2021. Este banco de dados se encontra no menu lateral “Arquivos”
do curso. Em seguida, vamos calcular a frequência de casos em andamento
por município de residência atual e unir com a população residente. Por
último, vamos calcular a prevalência para todos os municípios do estado
e salvar esses cálculos no objeto
{prevalencia_hans_ac}.
Acompanhe o código com atenção e replique-o no seu computador:
# Importação da base de casos do SINAN para o R, utilizando o pacote foreign.
base_hans <- read.dbf('Dados/base_hans_ac.dbf', as.is = TRUE)
casos_hans_ac_21 <- base_hans |>
# Filtrando para os casos que o Tipo de Alta está em branco (TPALTA_N),
# denotando os casos em acompanhamento.
filter(is.na(TPALTA_N)) |>
# Sumarização dos casos por município de atendimento (MUNIRESAT).
count(MUNIRESAT)
prev_casos_ac <- casos_hans_ac_21 |>
# Unindo a tabela de casos à tabela de população pelo geocódigo do município de
# atendimento.
left_join(pop_ac, by = c("MUNIRESAT" = "codigo")) |>
# Filtrando os municípios que não foram encontrados na união.
filter(!is.na(MUNIRESAT))
# Calculando a prevalência por município e seleção das colunas necessárias para o
# mapa.
prevalencia_hans_ac <- prev_casos_ac |>
mutate(prevalencia_2021 = (n / x2021) * 10000) |>
select(MUNIRESAT, municipio, prevalencia_2021)
# Visualizando a tabela
prevalencia_hans_ac#> MUNIRESAT municipio prevalencia_2021
#> 1 120001 Acrelândia 1.2721837
#> 2 120005 Assis Brasil 3.9220813
#> 3 120010 Brasiléia 2.9495262
#> 4 120013 Bujari 2.8376844
#> 5 120017 Capixaba 2.4429967
#> 6 120020 Cruzeiro do Sul 1.3368984
#> 7 120025 Epitaciolândia 4.7420834
#> 8 120030 Feijó 1.7149717
#> 9 120032 Jordão 1.1590172
#> 10 120033 Mâncio Lima 1.0181744
#> 11 120035 Marechal Thaumaturgo 0.5069195
#> 12 120038 Plácido de Castro 1.4890554
#> 13 120039 Porto Walter 4.0009602
#> 14 120040 Rio Branco 1.6688441
#> 15 120042 Rodrigues Alves 1.0117873
#> 16 120043 Santa Rosa do Purus 1.4507471
#> 17 120045 Senador Guiomard 2.5590719
#> 18 120050 Sena Madureira 1.4840570
#> 19 120060 Tarauacá 2.5154356
#> 20 120070 Xapuri 5.0337260
#> 21 120080 Porto Acre 2.6121937A tabela final será mostrada no seu painel Console.
Agora vamos escolher o método de classificação da variável
prevalencia_2021, presente no objeto
{prevalencia_hans_ac} para representar no mapa
coroplético.
Vários métodos podem ser calculados para a escolha da classificação da variável. Mas é sempre importante destacar: não há método certo ou errado. A melhor escolha é aquela que leve em consideração a forma que a variável se distribui e o número de unidades territoriais a serem representadas. A depender do método, a aparência do mapa muda. Áreas que poderiam ser consideradas prioritárias para alguma ação de prevenção, deixam de ser, simplesmente pela mudança da classificação.
Essa classificação irá criar grupos (classes) e contabilizar quantos municípios possuem a prevalência entre os intervalos classificados. Há várias maneiras de definir as classes. Vamos apresentar os principais métodos:
a) Intervalo igual: essa classificação define o intervalo considerando o máximo e mínimo da variável para dividir o número de classes. Cada classe possui um valor igual de diferença entre as outras. É de fácil entendimento e é adequada para distribuições uniformes e simétricas, além de poder ser usada para comparações entre mapas.
b) Quantil: essa classificação define a quantidade igual de observações em cada classe (quantis). É adequada para distribuições uniformes, simétricas e assimétricas e permite a comparação entre mapas.
c) Jenks: essa classificação utiliza o método de Jenks, que se baseia na semelhança (e diferença) de valores entre as unidades mapeadas. Na estatística, entende-se que esse método busca minimizar a variância dentro das classes e maximizar a variância entre as classes. É adequado para distribuições simétricas, mas a comparação entre mapas deve ser cautelosa.
Para ilustrar essas classificações, vamos apresentadas com os histogramas e mapas, na Figura 14:
Figura 14: Exemplo de métodos de definição de classes para mapas coropléticos.
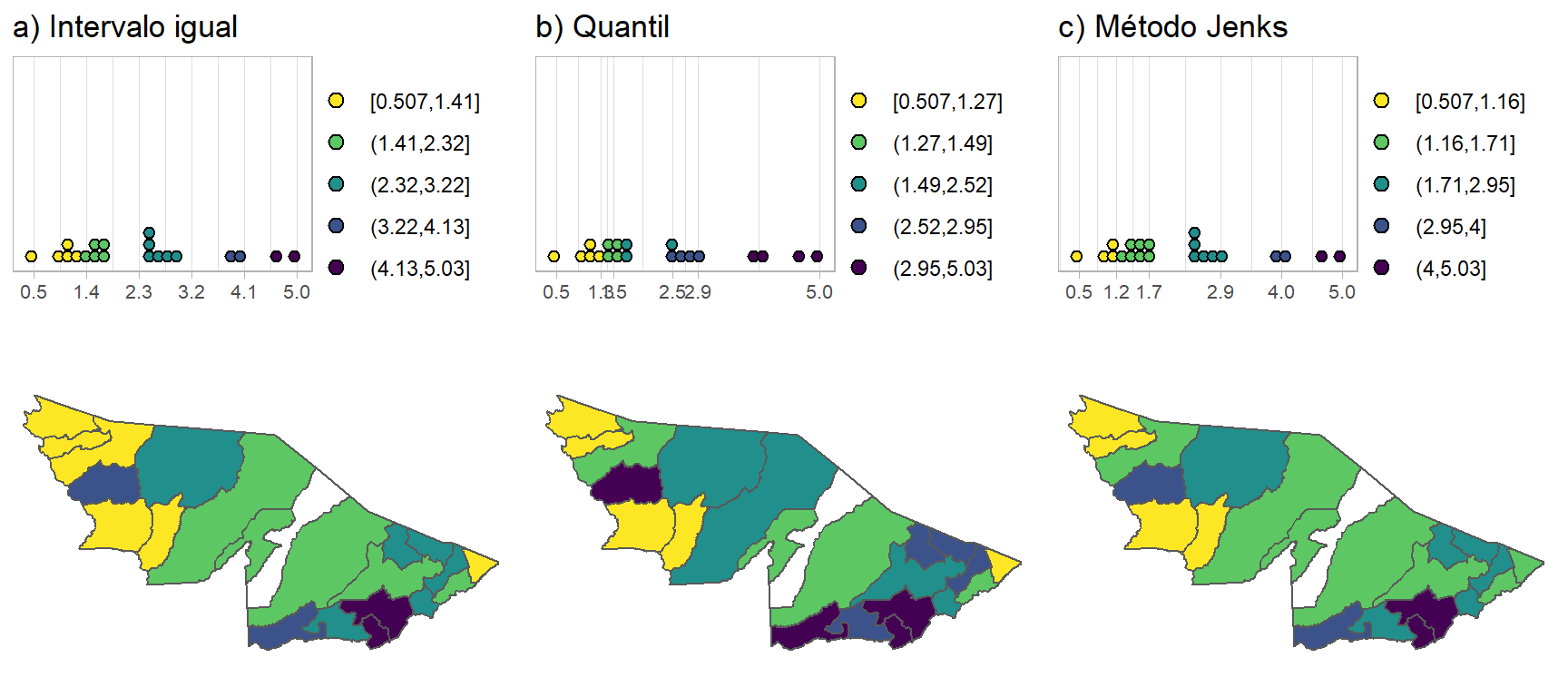
Perceba que o mapa muda de acordo com a a classificação dos dados de prevalência utilizada. Municípios que ficariam com cores mais escuras numa classificação e, assim, representando valores mais altos, podem ser representados de forma diferente se mudar a classificação. Novamente reforçamos que a escolha será conforme o método que melhor represente o fenômeno mostrado no mapa e atenda ao objetivo do Analista.
Após termos uma introdução aos métodos de classificação, vamos
visualizar a prevalência de hanseníase entre os municípios do Acre
utilizando o método de quantis com o pacote mapsf, pois a
distribuição dos dados está mais uniforme. Primeiro, vamos unir a tabela
de prevalência com os municípios, utilizando como geocódigo a variável
com código do IBGE em ambas as tabelas. Execute o código a seguir:
# Unindo a tabela `prevalencia_hans_ac` com `ac_municipios_5880`
# com a função left_join() e salvando no objeto `prevalencia_mun`
prevalencia_mun <- left_join(
x = ac_municipios_5880,
y = prevalencia_hans_ac,
# A ligação é feita pela correspondência entre as colunas
# "cod_mun" e "MUNIRESAT"
by = c("cod_mun" = "MUNIRESAT")
) Em seguida, vamos utilizar a função mf_choro() para
visualizar o mapa, definindo os seguintes argumentos:
var: coluna com os dados a serem plotados;breaks: classificação utilizada para divisão das classes;pal: paleta de cores. Para visualização das paletas disponíveis excute a funçãohcl.pals()no console;leg_pos: posição da legenda;leg_title: o título da legenda;leg_no_data: texto a ser mostrado sempre que houver município sem dados.
Reproduza os próximos códigos com atenção e observe o resultado gerado:
# Plotando o objeto prevalencia_mun com uso da função mf_map()
mf_map(prevalencia_mun) |>
# Adicionando camada de mapa coroplético com a função mf_choro()
mf_choro(
# Definindo a variável que será utilizada para a cor de preenchimento
var = "prevalencia_2021",
# Definindo os intervalos de valores
breaks = "quantile",
# Definindo a paleta de cores para "viridis"
pal = "Viridis",
# Definindo a posição da legenda para a região "inferior e à esquerda"
leg_pos = "bottomleft1",
# Definindo o título da legenda
#
leg_title = "Prevalência \nHanseníase \n2021",
# Inserindo caixa adicional para a legenda
leg_no_data = "Sem dados"
)Figura 15: Exemplo de elaboração de mapa coroplético com layout completo.
# Definindo a posição da seta de norte para a região "superior e à direita" com a
# função mf_arrows()
mf_arrow(pos = "topright")
# Inserindo a escala com a função mf_scale()
mf_scale()
# Definindo o título do mapa e definindo o tamanho do texto
# para encaixar melhor no título
mf_title(txt = "Distribuicao espacial da prevalência de Hanseníase no Estado do
Acre segundo municipio, 2021.",
cex = 0.8)
# Definindo informações complementares
mf_credits(txt = "Fonte: IBGE/2021 e SINAN/MS 2021.", pos = "bottomleft")Figura 16: Exemplo de elaboração de mapa coroplético com layout completo.
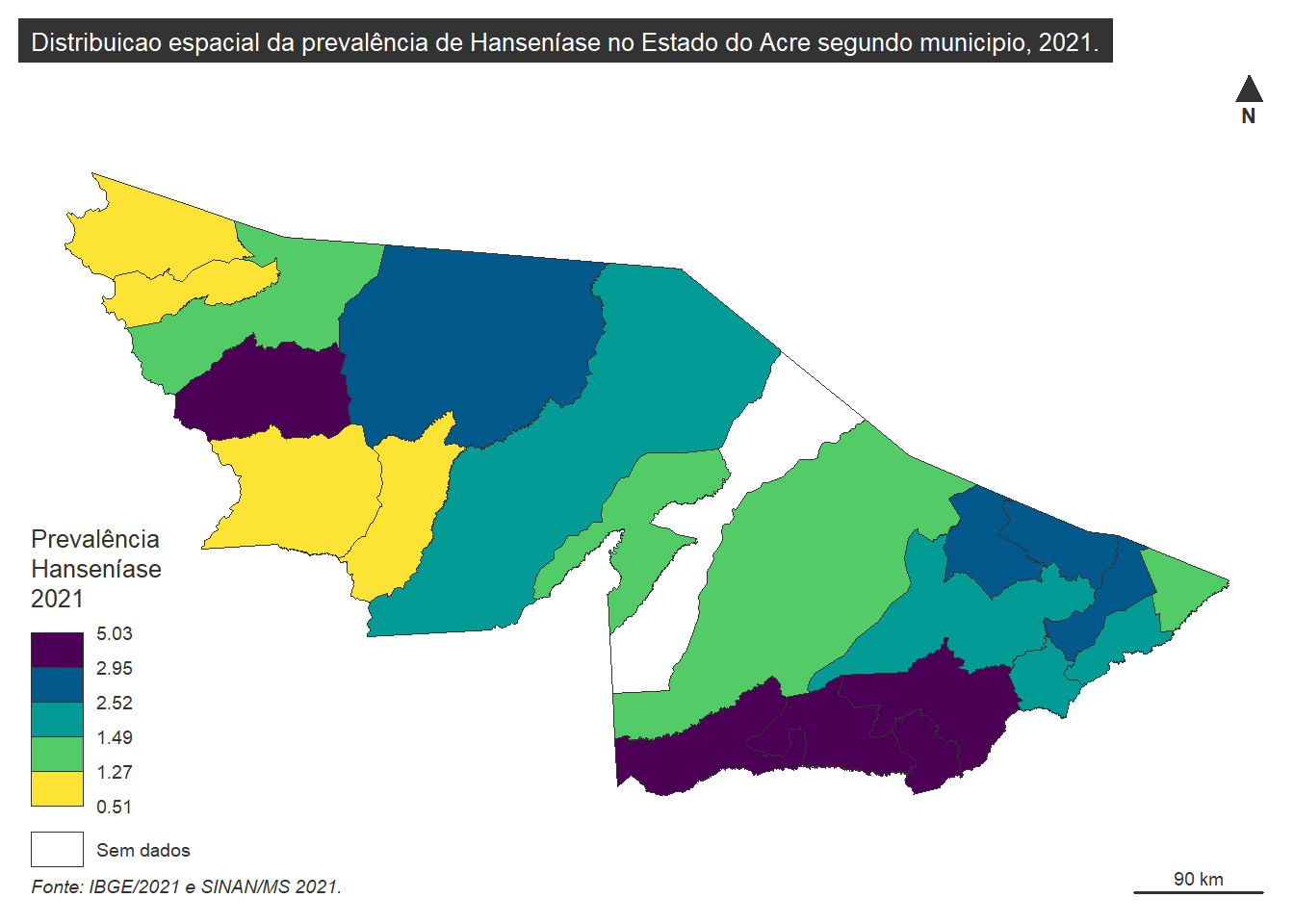
Ao utilizarmos a a divisão por quantis em cinco classes, temos que 20% dos municípios estão classificados com valores altos. Dessa forma, ao analisarmos a Figura 15, percebemos que entre os municípios que apresentaram prevalência acima de 2,93 casos por 100 mil habitantes, quatro localizam-se na região sul do Acre e um na região oeste. NO entnado, apenas um possui prevalência registrada em 5 casos por 100 mil habitantes. Os municípios que registram os 20% mais baixos encontram-se todos na região oeste do estado.
É importante que, com esses dados, o analista da vigilância, juntamente com a área técnica que coordena ações contra a hanseníase, cruze dados socioeconômicos, de infraestrutura de saúde, de saneamento básico, de demografia e de situação do atendimento de Hanseníase nos locais acometidos. O mapa não é o final de uma análise. Sempre será o ponto de partida para várias ações de saúde.
5.3.2 Coeficiente de Mortalidade Infantil no município de São Paulo
A taxa de mortalidade infantil representa o número de óbitos ocorridos em crianças menores de um ano de idade por mil nascidos vivos no mesmo período. Este indicador é muito importante por permitir avaliar as condições de vida e de saúde de uma dada população. Com o cálculo da sua taxa, é possível estimar o risco de uma criança morrer antes de chegar a um ano de vida.
O indicador de mortalidade infantil, em especial a mortalidade pós-neonatal, quando elevadas refletem as precárias condições de vida e saúde e valores abaixo do nível de desenvolvimento social e econômico. Já taxas reduzidas podem sinalizar bons indicadores sanitários e sociais, mas também podem encobrir más condições de vida em segmentos sociais específicos.
Que tal olharmos um pouco para indicadores dentro dos municípios? Nessa perspectiva, considere que nossa tarefa é comparar a distribuição espacial do coeficiente de mortalidade infantil no município de São Paulo em três anos diferentes, 2019 a 2021. Portanto, precisamos criar um mapa coroplético para cada ano.
Para esse objetivo, vamos utilizar um outro pacote para elaboração de
mapas temáticos: o tmap. Esse pacote possui muitas
semelhanças com o mapsf, possuindo uma grande flexibilidade
para elaboração de mapas e para adequações dos elementos de comunicação
e cartográficos.
Para realizar nossa tarefa, vamos importar dois arquivos:
um arquivo com a extensão “csv” baixado do Tabnet do município de São Paulo (Clique aqui para acesso). Neste arquivo temos o coeficiente de mortalidade infantil calculado para cada distrito administrativo do município de São Paulo, cuja fonte é a Secretaria Municipal de Saúde de São Paulo (SMS-SP).
um arquivo vetorial com a extensão “gpkg” dos distritos administrativos. O distrito administrativo é a unidade territorial padrão de localização dos eventos relacionados à saúde em todos os sistemas de informação do SUS no município de São Paulo, sendo a menor área intramunicipal disponível para download (Clique aqui para acesso). A fonte é o Sistema Municipal de Planejamento e Gestão Urbana da Prefeitura de São Paulo, que disponibiliza o dado pelo Geosampa, um sistema de informações georreferenciadas de São Paulo.
Como vimos anteriormente, a ligação entre os dados não-gráficos e gráficos se dá pelo geocódigo. Mas, em algumas situações, o geocódigo não está disponível. Dessa forma, uma alternativa é utilizar o nome das unidades territoriais como ligação. Então, vamos realizar o procedimento necessário para padronizar os nomes para que fiquem iguais e permitam uma conexão entre as bases. Vamos lá?
Vamos começar importando o arquivo {cmi_sp_19_21.csv}
com os dados de mortalidade infantil do município de São Paulo entre
2019 e 2021. Este arquivo se encontra no menu lateral “Arquivos” do
curso. Note que, no código abaixo, vamos utilizar o argumento
locale na função read_csv2() para corrigir a
codificação dos caracteres do arquivo para os padrões brasileiros.
Replique o código no seu RStudio:
# Importando o arquivo{`CID-cmi_sp_19_21.csv`} para o `R`
cmi_sp_19_21 <- read_csv2("Dados/cmi_sp_19_21.csv",
locale = locale(encoding = "ISO-8859-1"))#> ℹ Using "','" as decimal and "'.'" as grouping mark. Use `read_delim()` for more
control.#> Rows: 98 Columns: 5
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ";"
#> chr (5): Dist Administrativo resid, 2019, 2020, 2021, Total
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.# Visualizando o objeto
cmi_sp_19_21#> # A tibble: 98 × 5
#> `Dist Administrativo resid` `2019` `2020` `2021` Total
#> <chr> <chr> <chr> <chr> <chr>
#> 1 Água Rasa 5,05 5,34 5,13 5,17
#> 2 Alto de Pinheiros 3,23 - 15,21 5,80
#> 3 Anhanguera 7,43 11,49 8,51 9,08
#> 4 Aricanduva 7,27 12,84 11,29 10,43
#> 5 Artur Alvim 4,13 13,16 10,13 8,89
#> 6 Barra Funda 7,71 2,82 2,75 4,51
#> 7 Bela Vista 14,08 9,42 10,40 11,51
#> 8 Belém 6,32 11,74 17,70 11,57
#> 9 Bom Retiro 5,78 2,12 8,44 5,46
#> 10 Brás 19,49 10,80 26,74 18,66
#> # … with 88 more rows
#> # ℹ Use `print(n = ...)` to see more rowsPodemos perceber que o arquivo importado possui 5 colunas e 98 linhas. Os nomes das colunas possuem espaços e números e uma coluna “Total” que não será necessária. Além disso, as colunas que armazenam os coeficientes de mortalidade infantil estão como character.
Então, nosso próximo passo é padronizar as colunas e, principalmente, os nomes dos distritos administrativos, retirando acentos e sinais de pontuação (hífen, vírgulas e pontos) que, eventualmente, podem estar presentes. Vamos realizar uma pivotagem das colunas, levando os dados de mortalidade infantil para apenas uma coluna, pois como nosso objetivo é comparar todos os anos. Assim, teremos que ter uma coluna com os anos e outra com os valores correspondentes.
Para realizar esses procedimentos, vamos utilizar funções dos pacotes
janitor, stringr e stringi,
instalados e carregados anteriormente. Acompanhe o código a seguir com
muita atenção aos comentários, que explicam as ações que estão sendo
realizadas. Também o replique no seu computador:
# Criando um novo objeto com as correções feitas
cmi_sp <- cmi_sp_19_21 |>
# Padronizando o nome das colunas utilizando a função `clean_names` do
# pacote `janitor`
clean_names() |>
# Retirando a coluna `total`, pois não será necessária
select(-total) |>
# Retirando as linhas que não corresponde a nenhum distrito administrativo,
# utilizando a função `filter()` do pacote `dplyr`
filter(
dist_administrativo_resid != "Endereço não localizado" ,
dist_administrativo_resid != "Ignorado"
) |>
# Padronizando as colunas de ano para uma coluna só utilizando a função
# `pivot_longer()` do pacote `dplyr`. Note que vamos retirar a letra "x",
# adicionada pela função `clean_names()`
pivot_longer(
cols = c(x2019, x2020, x2021),
names_to = "ano",
values_to = "cmi",
names_prefix = "x"
) |>
# Criando as novas colunas corrigidas
mutate(
# Primeiro criando a coluna que receberá os nomes dos distritos
# administrativos corrigidos (passaremos para maiúsculo utilizando a
# função `str_to_upper()` do pacote `stringr` e retiraremos os acentos
# utilizando a função `stri_trans_general()` do pacote `stringi`)
ds_nome = str_to_upper(dist_administrativo_resid) |>
stri_trans_general("latin-ascii"),
# Depois, a coluna que receberá os coeficientes corrigidos, utilizando a
# função `str_replace_all()` do pacote `stringr`, e transformados para
# valores numéricos utilizando a função `as.numeric()`
cmi_num = str_replace_all(cmi, "\\,", "\\.") |>
str_replace_all("\\-", NA_character_) |>
as.numeric()
)Pronto, a base está agora devidamente corrigida. Caso tenha dúvida sobre as funções utilizadas, sugerimos a Unidade 3 do curso básico “Análise de dados para a Vigilância em Saúde”.
Vamos visualizar as primeiras linhas da base corrigida. Digite no seu
RStudio:
# Visualizando as primeiras linhas do objeto `cmi_sp`
head(cmi_sp)#> # A tibble: 6 × 5
#> dist_administrativo_resid ano cmi ds_nome cmi_num
#> <chr> <chr> <chr> <chr> <dbl>
#> 1 Água Rasa 2019 5,05 AGUA RASA 5.05
#> 2 Água Rasa 2020 5,34 AGUA RASA 5.34
#> 3 Água Rasa 2021 5,13 AGUA RASA 5.13
#> 4 Alto de Pinheiros 2019 3,23 ALTO DE PINHEIROS 3.23
#> 5 Alto de Pinheiros 2020 - ALTO DE PINHEIROS NA
#> 6 Alto de Pinheiros 2021 15,21 ALTO DE PINHEIROS 15.2Com as colunas devidamente corrigidas, vamos importar o arquivo
vetorial dos distritos administrativos de São Paulo. O arquivo
{sp_da.gpkg} encontra-se disponível para download
no menu lateral “Arquivos” do curso. Vamos utilizar a função
read_sf() para a importação e vamos salvá-lo no objeto
chamado {distrito_adm_sp}. Acompanhe o código abaixo e
reproduza-o no seu computador:
# Importando o arquivo{`sp_da.gpkg`} para o `R`
distrito_adm_sp <- read_sf("Dados/sp_da.gpkg")
# Visualizando o objeto salvo
distrito_adm_sp#> Simple feature collection with 96 features and 7 fields
#> Geometry type: POLYGON
#> Dimension: XY
#> Bounding box: xmin: 313389.7 ymin: 7343743 xmax: 360618.2 ymax: 7416156
#> Projected CRS: SIRGAS 2000 / UTM zone 23S
#> # A tibble: 96 × 8
#> ds_areamt ds_subpref ds_sigla ds_nome ds_ar…¹ ds_cd…² ds_co…³
#> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
#> 1 NA SANTANA-TUCURUVI MAN MANDAQUI NA 05 51
#> 2 NA MOOCA MOO MOOCA NA 25 53
#> 3 NA CASA VERDE-CACHOEIRINHA LIM LIMAO NA 04 50
#> 4 NA JABAQUARA JAB JABAQUARA NA 15 38
#> 5 NA CIDADE ADEMAR CAD CIDADE AD… NA 16 22
#> 6 NA ITAQUERA ITQ ITAQUERA NA 27 37
#> 7 NA ITAQUERA JBO JOSE BONI… NA 27 47
#> 8 NA VILA PRUDENTE SLU SAO LUCAS NA 29 72
#> 9 NA MOOCA PRI PARI NA 25 56
#> 10 NA ITAQUERA PQC PARQUE DO… NA 27 57
#> # … with 86 more rows, 1 more variable: geom <POLYGON [m]>, and abbreviated
#> # variable names ¹ds_areakm, ²ds_cd_sub, ³ds_codigo
#> # ℹ Use `print(n = ...)` to see more rows, and `colnames()` to see all variable
namesNote que, ao visualizarmos o arquivo importado, percebemos que é um arquivo vetorial de 96 polígonos e no sistema de coordenadas consta UTM 23S (“Projected CRS: SIRGAS 2000 / UTM zone 23S”). Logo, o arquivo já está em um sistema de coordenadas planas, não sendo necessária qualquer transformação.
Perceba também que a variável chamada ds_nome, que é a
variável que contém os nomes dos distritos administrativos, já está em
letra maiúscula e sem acentos sendo, portanto, dispensada de quaisquer
correções.
Agora vamos unir o arquivo vetorial à tabela de coeficiente de
mortalidade infantil. A variável ds_nome, que agora está
presente nos dois arquivos, será a ligação entre os dois. Acompanhe o
script abaixo e replique-o em seu RStudio.
# Unindo a tabela `distrito_adm_sp` com `cmi_sp`
# com a função left_join() e salvando no objeto `cmi_sp_map`
cmi_sp_map <- left_join(
x = distrito_adm_sp,
y = cmi_sp,
# A ligação é feita pela variável `ds_nome`
by = "ds_nome"
)Perfeito. Com a união pronta, vamos criar o mapa temático para comparar os três anos. Novamente vamos criar um mapa coroplético, destacando os distritos intramunicipais com maior coeficiente de mortalidade infantil com uma cor mais intensa e aqueles com menores valores com cores mais claras. Utilizaremos a variável “cmi_num” mas, antes, vamos visualizar como os valores estão distribuídos.
Vamos utilizar a função hist(), nativa da linguagem
R, para visualizar os valores que vamos inserir no mapa.
Essa função possui como argumento principal x, que é onde
vamos explicitar a variável. Note que vamos usar o cifrão para indicar a
variável “cmi_num” da base {cmi_sp_map}. Acompanhe o código
abaixo e digite no seu computador:
hist(x = cmi_sp_map$cmi_num)Figura 17: Visualização da distribuição de uma variável utilizando histograma.
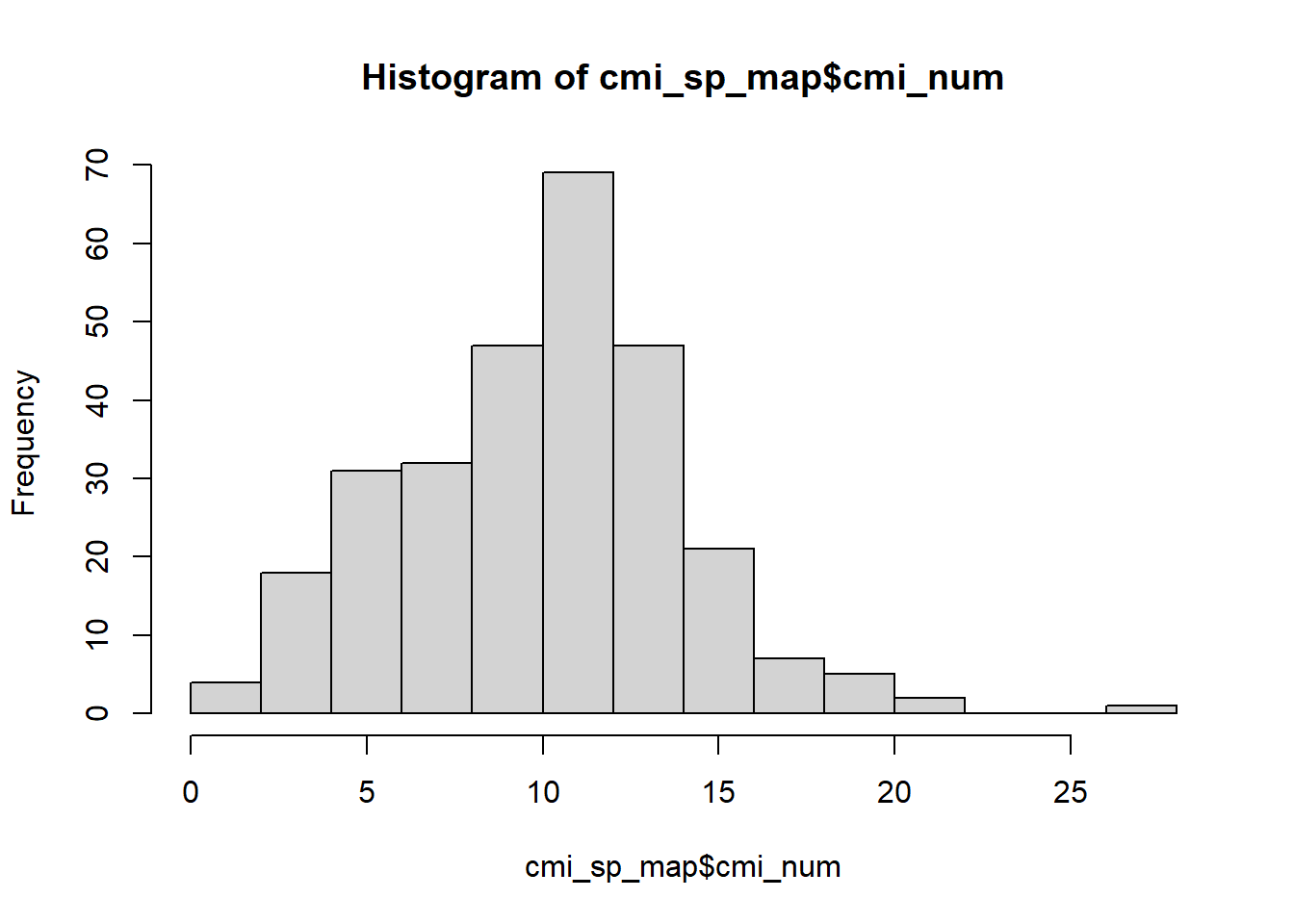
Como vamos comparar por anos, temos que visualizar uma só variável. Dessa forma, podemos notar que há poucos valores baixos, poucos valores altos e a maioria não centro do gráfico. Com essa distribuição, vamos utilizar a classificação de Jenks para criar a legenda do mapa coroplético.
Para isso, vamos utilizar as funções tm_shape() e
tm_polygons() do pacote tmap. A primeira
insere uma camada referente ao mapa base e a segunda insere o mapa com a
classificação dos valores coloridos conforme a paleta especificada. Os
argumentos são muito parecidos com a função mf_choro(),
utilizada anteriormente.
Também utilizaremos uma função bem interessante chamada
tm_facets(), que cria um mapa para cada ano. Isso
possibilitará compararmos o coeficiente de mortalidade infantil de forma
única.
Para inserir o título, a fonte dos dados, a escala e a seta de norte,
vamos utilizar as funções tm_layout(),
tm_credits(), tm_scale_bar() e
tm_compass(), respectivamente. Note que o pacote
tmap utiliza o símbolo de mais (+) para
sobrepor as camadas e elementos definidos pelas funções.
Acompanhe o código a seguir com especial atenção aos comentários pois apontaremos informações complementares para auxiliar no seu entendimento. Novamente replique o código no seu computador:
# Plotando o objeto `cmi_sp_map` com uso da função tm_shape().
# Esse será o nosso mapa base.
tm_shape(cmi_sp_map) +
# Adicionando camada de mapa coroplético com a função tm_polygons()
tm_polygons(
# Definindo a variável que será utilizada para a cor de preenchimento
col = "cmi_num",
# Definindo os intervalos de valores e a classificação via "jenks"
n = 5, style = "jenks",
# Definindo a paleta de cores para "viridis". Para inverter a direção
# das cores (do mais claro para o mais escuro), precisamos inserir
# o símbolo de menos antes do nome da paleta.
palette = "-viridis",
# Definindo o título da legenda. Usamos o marcador "\n" para pular linha
title = "Coeficiente \nde Mortalidade \nInfantil por mil \nnascidos vivos",
# Definindo o separador dos coeficientes na legenda
legend.format = list(text.separator = "a"),
# Inserindo caixa adicional para a legenda onde não há dados
colorNA = "white", textNA = "Sem dados"
) +
# Utilizando a função `tm_facets()` para criar um mapa para cada ano com o
# argumento `by` e definindo uma linha para a disposição dos mapas com o
# argumento `nrow`
tm_facets(by = "ano", nrow = 1) +
# Definindo a posição da seta de norte para a região
# "superior e à direita" com a função tm_compass(), com
# argumento `position`
tm_compass(position = c("right", "top")) +
# Inserindo a escala com a função tm_scale_bar()
tm_scale_bar() +
# Definindo o título do mapa e definindo o tamanho do texto
# para encaixar melhor no título
tm_layout(main.title = "Coeficiente de Mortalidade Infantil por distritos\nadministrativos de São Paulo-SP, 2019 a 2021.") +
# Definindo informações complementares. Como teremos três mapas, um para
# cada ano, inserimos um vetor contendo a fonte dos dados aparecendo
# somente no primeiro mapa.
tm_credits(text = c("Fonte:\nSMS-SP;\nSMPGP-SP","",""), position = c("left", " bottom"))Figura 18: Exemplo de elaboração de mapa coroplético com comparação entre anos.
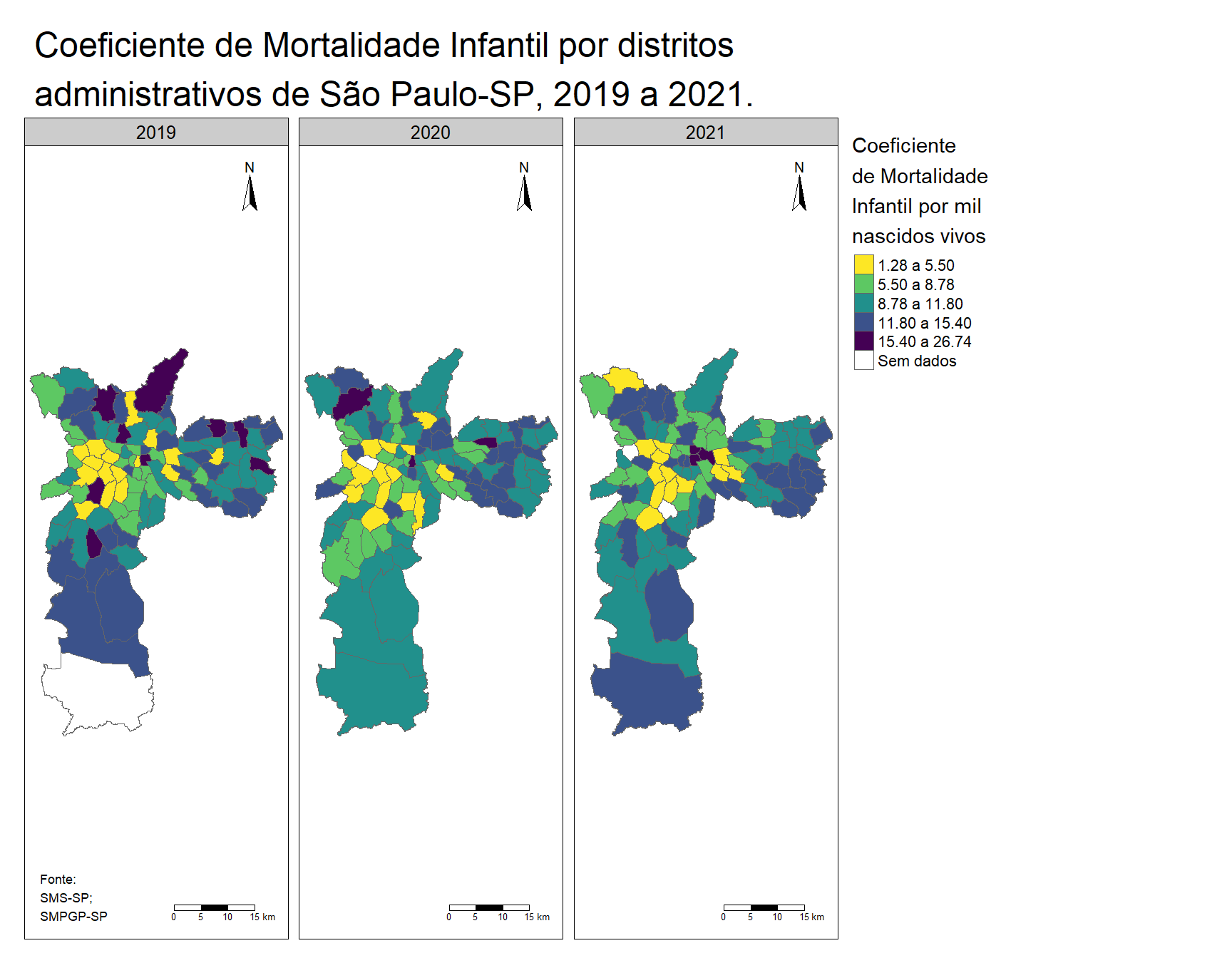
Muito bem, nosso mapa está pronto. Na Figura 17 é possível notar que há importantes desigualdades na ocorrência dos óbitos infantis entre as unidades administrativas de São Paulo, exigindo ações para compreender os motivos das diferenças e para eliminar as desigualdades observadas..
Percebeu como é interessante a comparação? Agora vamos entender um pouco sobre o mapa de fluxos?
5.4 Mapa de fluxos
Os mapas de fluxos representam os movimentos no espaço, onde a largura das linhas indica o volume do deslocamento de uma unidade territorial para outra, em números totais. Linhas mais grossas indicam maior quantidade de indivíduos se deslocando. No mapa apresentado, não são representadas rotas de deslocamento, mas sim os fluxos da origem e do destino.
A elaboração de mapas de fluxos não é um processo trivial, apesar de serem muito úteis na visualização do movimento em busca de atendimento de saúde. São necessários dados agregados que expressem a quantidade de deslocamentos de uma unidade para outra. A depender da ferramenta utilizada, são também necessárias as coordenadas da origem e do destino.
Para demonstrar a elaboração desse mapa, vamos utilizar variáveis selecionadas no Sistema de Informações Hospitalares (SIH), cujo diagnóstico principal foi por causas relacionadas à gravidez, parto ou puerpério, classificadas no Capítulo XV da CID-10. Realizamos um filtro das internações em que houve deslocamento da mulher entre municípios do estado do Acre, no ano de 2021.
Primeiramente, vamos importar a base que se encontra no formato
“*.dbf”. Para isso, vamos utilizar o pacote foreing.
Execute o comando a seguir no seu computador:
# Carregando a base de dados para o objeto ac_internacao utilizando
# a função read.dbf()
ac_internacao <- read.dbf("Dados/ac_sih.dbf", as.is = TRUE)Vamos visualizar apenas as primeiras linhas da tabela importada. Replique o código abaixo:
# Visualizando as primeiras linhas da tabela importada
head(ac_internacao)#> UF_ZI ANO_CMPT MES_CMPT MUNIC_RES VAL_TOT DT_INTER DT_SAIDA DIAG_PRINC
#> 1 120000 2021 01 120025 562.73 20210115 20210117 O821
#> 2 120000 2021 01 120010 109.24 20210114 20210116 O234
#> 3 120000 2021 01 120025 133.24 20210115 20210118 O234
#> 4 120000 2021 01 120010 110.24 20210117 20210118 O998
#> 5 120000 2021 01 120010 109.24 20210112 20210114 O234
#> 6 120000 2021 01 120010 180.62 20210102 20210104 O034
#> MUNIC_MOV IDADE RACA_COR
#> 1 120010 16 03
#> 2 120010 24 03
#> 3 120010 16 03
#> 4 120010 22 03
#> 5 120010 16 03
#> 6 120010 28 01Agora, para criar o mapa de fluxo, vamos considerar as variáveis que representam o município de residência (MUNIC_RES) da mulher como a origem do deslocamento e município de internação (MUNIC_MOV) como o destino do deslocamento que realizou a internação relacionada ao parto, gravidez e puerpério.
Em seguida, vamos contabilizar quantos deslocamentos ocorreram no ano
de 2021 entre o par de município origem e destino. Para isso, vamos
utilizar a função count() do pacote dplyr.
Além disso, vamos excluir as internações onde a origem e o destino são
iguais, ou seja, é o mesmo município e o paciente foi internado no
município onde reside. Também vamos desconsiderar os deslocamentos com
volume menor que 10. Essas operações serão salvas em um novo objeto
chamado {ac_capitulo_15}. Acompanhe o código abaixo com
atenção e replique no seu RStudio:
# Criando uma nova tabela com o nome ac_capitulo_15
ac_capitulo_15 <- ac_internacao |>
# Contando a frequência de registros por município de residência
# (coluna MUNIC_RES) e município de internação (coluna MUNIC_MOV)
count(MUNIC_RES, MUNIC_MOV) |>
# Filtrando os registros em que o município de residência difere
# do município de internação e com uma frequência maior ou igual a 10
filter(MUNIC_RES != MUNIC_MOV, n >= 10)Agora, com a frequência do deslocamento município de origem e
município de destino calculada, vamos unir esses dados ao mapa. Dessa
forma, criaremos as referências geográficas dos municípios de origem e
de destino para a criação das linhas de ligação entre os municípios
devidamente espacializadas. Para isso, vamos utilizar a função
mf_get_links() do pacote mapsf e informar os
seguintes argumentos:
x: um arquivo vetorial de municípios (vamos utilizar a {ac_municipios_5880});x_id: a variável do arquivo vetorial a ser utilizada como o geocódigo (“cod_mun”);df: uma base de frequência de deslocamentos {ac_capitulo_15};df_id: um vetor contendo as variáveis de origem e de destino, respectivamente (no caso “MUNIC_RES” e “MUNIC_MOV”).
Observe e reproduza o código abaixo no seu computador:
# Criando as linhas de ligação com a frequência de deslocamento
ac_deslocamentos <- mf_get_links(
x = ac_municipios_5880, # um arquivo vetorial de municípios
x_id = "cod_mun", # variável de ligação
df = ac_capitulo_15, # arquivo de frequência de deslocamentos
df_id = c("MUNIC_RES", "MUNIC_MOV") # variáveis de origem e destino
)Ao visualizar as primeiras linhas do objeto
ac_deslocamentos, você perceberá que, para cada par de
município de residência e município de internação, foi calculada a
frequência de deslocamentos entre estes municípios e sua devida ligação
geográfica.
head(ac_deslocamentos)#> Simple feature collection with 6 features and 3 fields
#> Geometry type: LINESTRING
#> Dimension: XY
#> Bounding box: xmin: 3250263 ymin: 8762143 xmax: 3580225 ymax: 8904710
#> Projected CRS: SIRGAS 2000 / Brazil Polyconic
#> MUNIC_RES MUNIC_MOV n geometry
#> 1 120001 120040 190 LINESTRING (3580225 8873782...
#> 2 120005 120010 122 LINESTRING (3250263 8762143...
#> 3 120005 120040 31 LINESTRING (3250263 8762143...
#> 4 120010 120040 53 LINESTRING (3337263 8770332...
#> 5 120013 120040 95 LINESTRING (3444644 8904710...
#> 6 120017 120040 163 LINESTRING (3485784 8808455...O próximo passo é definir o mapa base que, nessa prática, será
{ac_municipios_5880}, e definir uma cor de preenchimento.
Em seguida, vamos utilizar a função mf_grad() para
representar os deslocamentos de forma gradual, aumentado a espessura da
linha conforme aumenta a frequência de deslocamento entre os municípios.
Vamos ainda definir os seguintes argumentos:
x: a base de dados com os deslocamentos espacializados criados com a funçãomf_get_links();var: coluna com os dados a serem plotados;breaks: classificação utilizada para divisão das classes (quantil);n_breaks: números de classes (como temos poucos registros, utilizaremos 3 classes);leg_pos: posição da legenda;leg_title: o título da legenda;col: cor das linhas de deslocamentos.
Observe o código abaixo com atenção e reproduza-o no seu
RStudio.
# Plotando o objeto `ac_municipios_5880` com uso da função mf_map()
# O argumento "col" define a cor de preenchimento utilizando o código de
# cor hexadecimal
mf_map(ac_municipios_5880, col = "#FAFAFA")
# Inserindo camada indicando os descolamentos com uso da função mf_grad()
mf_grad(
# Definindo o objeto com a frequência sobre os deslocamentos
x = ac_deslocamentos,
# Definindo a variável que indicará a espessura da linha conforme a frequência
var = "n",
# Definindo o número mínimo de intervalos para os valores de espessura
nbreaks = 3,
# Definindo o método de classificação dos intervalos para quantis
breaks = "quantile",
# Definindo a espessura da linha relativa a cada intervalo
lwd = c(.7, 3, 7),
# Definindo a posição da legenda para "inferior e à esquerda"
leg_pos = "bottomleft1",
# Definindo o título do gráfico
leg_title = "Número de fluxos",
# Definindo a cor da linha com o código de cor hexadecimal.
# Para definir a opacidade, inserimos dois dígitos no final do
# código. Dessa forma, nossas linhas ficarão mais transparentes,
# melhorando a visualização
col = "#5DC86395"
)
# Definindo a posição da seta de norte para a
# "superior e à direita" com a função mf_arrows()
mf_arrow(pos = "topright")
# Inserindo a escala com a função mf_scale()
mf_scale()
# Definindo o título do mapa e definindo o tamanho do texto
# para encaixar melhor no título
mf_title(txt = "Fluxo de deslocamento das internações de mulheres por gravidez, parto e puerpério, Acre, 2021.",
cex = 0.8)
# Inserindo informações complementares
mf_credits(txt = "Fonte: IBGE/2021 e SINAN/MS 2021.", pos = "bottomleft")Figura 19: Exemplo de elaboração de mapa de fluxos com layout completo.
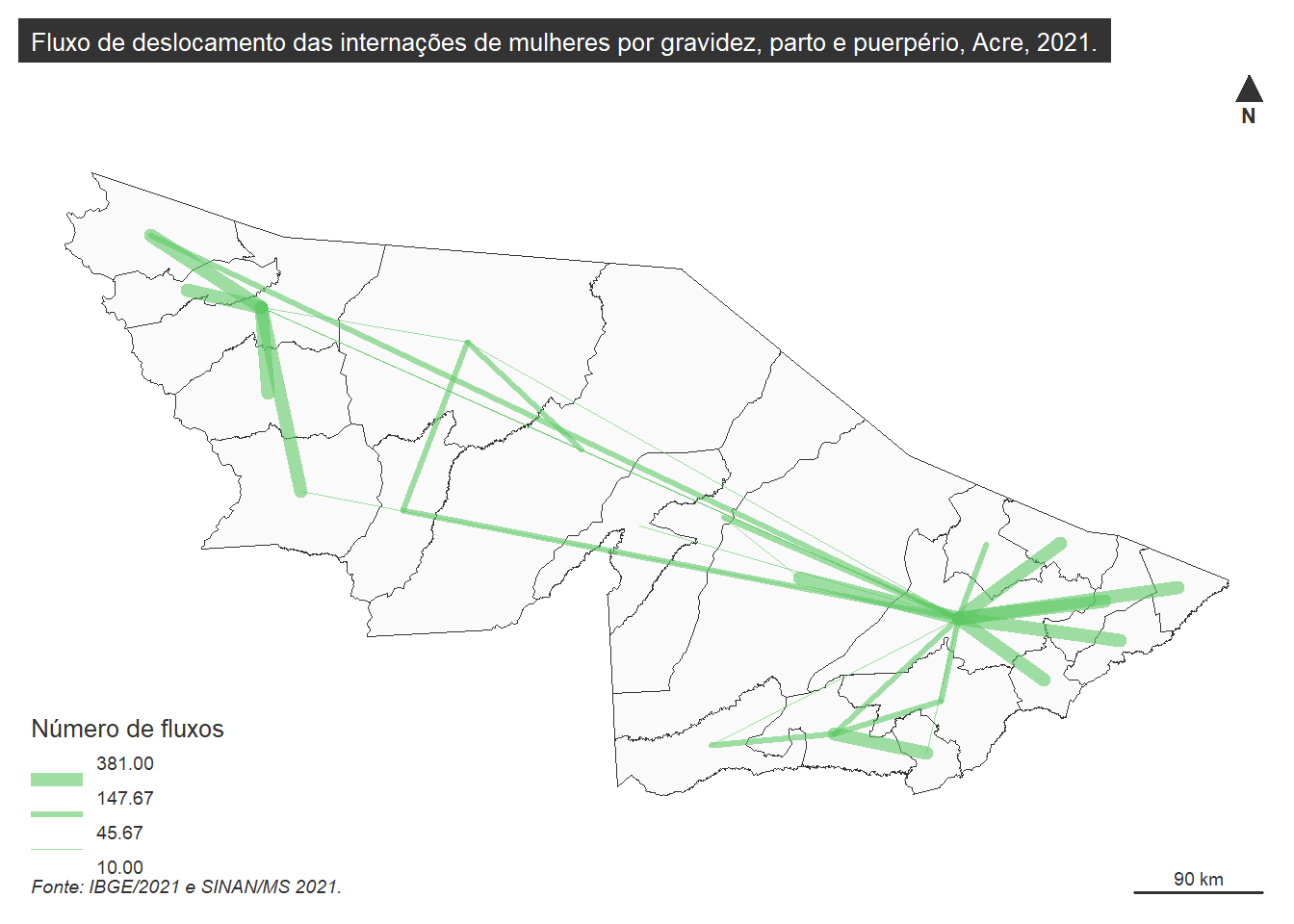
Ao analisarmos a Figura 19 percebemos que dois municípios concentram as internações de mulheres relacionadas a gravidez, parto ou puerpério. Um na região sul e outro na região oeste do estado. Isso pode ser devido à localização da referência hospitalar nestes municípios, pactuação para atendimento feita entre gestores ou demanda espontânea das mulheres. Entretanto, é cabível avaliar se esse deslocamento gera algum tipo de impacto nas mulheres, causados pelo tempo do deslocamento, qualidade das vias de transporte utilizada ou até suporte no município de destino. Por ser um procedimento de especialidade básica, mais investigações podem ser envidadas.
Neste curso, mostramos muitos exemplos que utilizam as áreas geográficas de municípios em um estado. Mas, é totalmente possível replicar os códigos apresentados em áreas menores, como bairros de um município. O mapa pode evidenciar situações na realidade local que, quando a análise é apenas por tabelas, não é possível identificar. Com uma análise exploratória bem feita é possível enriquecer muito as análises da Vigilância em Saúde.

A linguagem R oferece excelentes ferramentas que
facilitam desde abordagens básicas como importação e visualização de
dados espaciais, até robustas técnicas de modelagem estatística
espacial. Inclusive, há uma seção exclusiva para análise dados espaciais
dentro do CRAN https://cran.r-project.org/web/views/Spatial.html, onde
são listados dezenas de pacotes separados por tema.
Nossos cursos
Pronto, chegamos ao final deste curso! Agora você já conhece as
principais ações para criar mapas epidemiológicos com o apoio da
linguagem de programação R. Quer seguir a diante no
aprendizado? Você encontrará outras etapas para aprofundamento das
análises de dados em Vigilância em Saúde nos outros cursos. Aproveite e
já faça sua inscrição nos cursos abaixo clicando nos links:
- Análises de dados para Vigilância em Saúde - curso básico.
- Visualização de dados de interesse para a Vigilância em Saúde.
- Produção automatizada de relatórios na Vigilância em Saúde.
- Construção de diagramas de controle na Vigilância em Saúde.
- Linkage de bases de dados de saúde.
- Construção de painéis (dashboards) para monitoramento de indicadores de saúde.