


Assista ao vídeo de apresentação do módulo 4
O uso de estatísticas básicas para vigilância em saúde
Para seguir com este módulo você deve saber como importar dados de diferentes fontes, limpar e transformar textos e datas, criar tabelas com filtros escolhidos, unir dados de diversas fontes e exportar os dados tratados para diferentes formatos. Todo esse conteúdo nós vimos nos três primeiros módulos do curso. Lembre-se que você pode sempre voltar a eles para relembrar os códigos e dicas.
Neste módulo iremos aprender algumas das principais métricas para
análise de dados utilizando o software R. Estas métricas
são usadas dentro do fluxo de dados que você aprendeu no módulo anterior
para analisar e investigar os diversos sistemas de informação,
construindo um conjunto de dados de interesse e resumindo suas
principais características. Estas etapas são fundamentais para o
planejamento, o monitoramento e a avaliação das ações de vigilância em
saúde.
Ao final deste módulo, você será capaz de:
- realizar os principais cálculos para análise exploratória de dados;
- calcular frequência absoluta e relativa;
- calcular média, mediana e quartis;
- avaliar a distribuição e a dispersão de dados.
1. Análise exploratória de dados da Vigilância em Saúde
Para iniciar um relatório epidemiológico que narre a situação de um agravo, doença ou evento de saúde o profissional de vigilância deve realizar a análise exploratória de seus dados. Para manipular bancos de dados de forma eficiente, garantindo segurança à análise, o profissional deve possuir uma metodologia de compreensão e organização dos dados.
Para dar início a esta etapa, como primeiros passos para uma análise segura e reproduzível, o profissional de vigilância em saúde deve conhecer a estrutura de sua base de dados. Para isto deve sempre se fazer as seguintes perguntas:
- Quais informações estão presentes no banco de dados?
- Quais são as variáveis que o compõem?
- Quais os formatos dessas variáveis: textos, números, datas, categorias?
- O que cada linha significa?
Neste tópico iremos aprender como obter uma descrição básica dos dados escolhidos e responder a cada uma das perguntas listadas acima. Ao final seremos capazes de garantir a validade dos dados analisados e produzir nossa análise de situação de saúde com segurança.

Lembre-se de ter em mãos durante sua análise exploratória um dicionário de dados, documento que descreve os dados que serão utilizados: nomes ou variáveis, objetos, a estrutura dos dados ou suas fontes.
O dicionário de dados pode ser chamado também em alguns momentos de glossário de dados.
Crie o hábito de consultar o dicionário de dados dos sistemas de informações que irá analisar! Caso o sistema não possua, você pode construir seu próprio dicionário de dados o que ampliará sua compreensão da estrutura e memorização das variáveis do banco.
Vamos praticar! Para nossa análise exploratória do Estado de Rosas
utilizaremos a base de dados {NINDINET.dbf}, armazenada no
diretório “bases” do curso e que já utilizamos anteriormente. Carregue
os pacotes do tidyverse e foreign, e em
seguida importe o banco de dados para o ambiente do
RStudio. Lembre-se que os pacotes no R são
bibliotecas que organizam e padronizam a distribuição de funções do
R.
Acompanhe o script abaixo e não se preocupe com os pacotes novos que utilizaremos, eles serão explicados de forma detalhada no momento de aplicação neste módulo:
# carregando os pacotes necessários para análise
if(!require(tidyverse)) install.packages("tidyverse");library(tidyverse)
if(!require(foreign)) install.packages("foreign");library(foreign)
if(!require(DescTools)) install.packages("DescTools");library(DescTools)
if(!require(summarytools)) install.packages("summarytools");library(summarytools)
if(!require(gtsummary)) install.packages("gtsummary");library(gtsummary)# criando objeto do tipo dataframe (tabela) {`dados`} com a base de dados
# {`NINDINET.dbf`}
dados <- read.dbf(file = 'Dados/NINDINET.dbf')Agora, vamos visualizar o total de linhas e colunas da base de dados,
sua estrutura, o tipo de variável de cada coluna e seus respectivos
primeiros valores da tabela dados. Para isso utilizaremos a
função glimpse():
# utilizando a função glimpse()
glimpse(dados)#> Rows: 27,621
#> Columns: 62
#> $ NU_NOTIFIC <fct> 7671320, 0855803, 8454645, 3282723, 9799526, 7275624, 82477…
#> $ TP_NOT <int> 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,…
#> $ ID_AGRAVO <fct> A509, W64, X58, A90, B19, A90, A90, Y09, A90, W64, A90, A90…
#> $ CS_SUSPEIT <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
#> $ IN_AIDS <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
#> $ CS_MENING <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
#> $ DT_NOTIFIC <date> 2012-04-11, 2010-09-17, 2010-10-19, 2008-04-14, 2011-06-20…
#> $ SEM_NOT <fct> 201215, 201037, 201042, 200816, 201125, 200807, 200750, 201…
#> $ NU_ANO <int> 2012, 2010, 2010, 2008, 2011, 2008, 2007, 2011, 2008, 2011,…
#> $ SG_UF_NOT <int> 61, 61, 61, 61, 61, 61, 61, 61, 61, 61, 61, 61, 61, 61, 61,…
#> $ ID_MUNICIP <int> 610213, 610213, 610213, 610213, 610213, 610213, 610213, 610…
#> $ ID_REGIONA <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
#> $ ID_UNIDADE <int> 256100, 180142, 559191, 180142, 480722, 570404, 319816, 289…
#> $ DT_SIN_PRI <date> 2012-04-05, 2010-09-09, 2010-10-19, 2008-04-11, 2011-04-02…
#> $ SEM_PRI <fct> 201214, 201036, 201042, 200815, 201113, 200806, 200749, 201…
#> $ DT_NASC <date> 2012-04-04, 1988-04-23, 1971-03-25, 1928-05-29, 2002-09-18…
#> $ NU_IDADE_N <int> 2001, 4022, 4039, 4079, 4008, 4054, 4032, 4014, 4037, 4011,…
#> $ CS_SEXO <fct> M, M, M, F, M, F, F, F, F, F, M, M, M, M, F, F, F, F, F, F,…
#> $ CS_GESTANT <int> 6, 6, 6, 9, 6, 9, 9, 9, 6, 5, 6, 6, 6, 6, 9, 9, 9, 9, 6, 5,…
#> $ CS_RACA <int> 4, 1, NA, 4, 4, 9, NA, 1, 9, 4, NA, 9, NA, NA, 9, NA, 1, 9,…
#> $ CS_ESCOL_N <fct> 10, NA, NA, 02, 01, 09, NA, 09, 09, 01, 10, 09, 10, NA, 09,…
#> $ SG_UF <int> 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33,…
#> $ ID_MN_RESI <int> 610213, 610213, 610250, 610213, 610250, 610213, 610213, 610…
#> $ ID_RG_RESI <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
#> $ ID_DISTRIT <fct> 05, 05, 05, 01, 01, 04, 05, 04, 01, 04, 01, 05, 04, 05, 03,…
#> $ ID_BAIRRO <fct> 020, 019, 020, 001, 001, 014, 020, 012, 003, 016, 003, 020,…
#> $ ID_LOGRADO <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
#> $ ID_GEO1 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
#> $ ID_GEO2 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
#> $ CS_ZONA <int> 1, 1, NA, 1, 1, 1, 1, 1, 1, 1, 1, 1, NA, 1, 1, 1, 1, 1, 1, …
#> $ ID_PAIS <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
#> $ NDUPLIC_N <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
#> $ IN_VINCULA <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
#> $ DT_INVEST <date> NA, NA, 2010-10-19, 2008-04-14, 2011-06-20, NA, NA, NA, 20…
#> $ ID_OCUPA_N <fct> NA, NA, NA, NA, 999991, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
#> $ CLASSI_FIN <int> NA, NA, NA, 5, 1, 8, 8, 1, 1, NA, 8, 1, 8, 8, 1, NA, 1, 8, …
#> $ CRITERIO <int> NA, NA, NA, 1, NA, NA, NA, NA, 2, NA, NA, 1, NA, NA, 2, NA,…
#> $ TPAUTOCTO <int> NA, NA, NA, NA, NA, NA, NA, NA, 1, NA, NA, 1, NA, NA, NA, N…
#> $ COUFINF <int> NA, NA, NA, NA, NA, NA, NA, NA, 61, NA, NA, 61, NA, NA, NA,…
#> $ COPAISINF <int> 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0,…
#> $ COMUNINF <int> NA, NA, NA, NA, NA, NA, NA, NA, 610213, NA, NA, 610213, NA,…
#> $ CODISINF <fct> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
#> $ CO_BAINFC <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 84, 0, 0, 0…
#> $ NOBAIINF <fct> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
#> $ DOENCA_TRA <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
#> $ EVOLUCAO <int> 1, NA, NA, NA, NA, NA, NA, NA, 1, NA, NA, 1, NA, NA, NA, NA…
#> $ DT_OBITO <date> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
#> $ DT_ENCERRA <date> NA, 2010-10-16, 2010-10-19, 2008-06-19, 2011-06-20, 2008-0…
#> $ DT_DIGITA <date> 2012-11-09, 2010-11-17, 2011-03-14, 2008-04-24, 2011-09-14…
#> $ DT_TRANSUS <date> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
#> $ DT_TRANSDM <date> NA, NA, NA, NA, NA, NA, NA, NA, 2008-07-10, NA, NA, NA, NA…
#> $ DT_TRANSSM <date> 2012-11-13, 2010-11-23, 2011-04-12, 2010-11-16, 2011-09-19…
#> $ DT_TRANSRM <date> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
#> $ DT_TRANSRS <date> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
#> $ DT_TRANSSE <date> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
#> $ NU_LOTE_V <fct> 2012049, 2010047, 2011015, 2010044, 2011038, 2010043, 20100…
#> $ NU_LOTE_H <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
#> $ CS_FLXRET <int> 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
#> $ FLXRECEBI <int> 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,…
#> $ MIGRADO_W <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
#> $ CO_USUCAD <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
#> $ CO_USUALT <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…Observe que ao executarmos o comando glimpse(dados), a
função lhe retornará o nome de todas as variáveis da base. Estas
variáveis estão identificadas a partir de estruturas com o seguinte
padrão:
int: variáveis compostas por números inteiros;dbl: variáveis numéricas compostas por números reais;date: variáveis no formato de data (aaaa/mm/dd);fct: variáveis categóricas (codificadas como “fatores” ou “factors”), e o número de categorias nesta variável (levels);chr: variáveis no formato de strings de texto (character).
Você poderá também visualizar os dados de outra maneira, ou seja, de
forma mais resumida. Para isto deve selecionar ou clicar no nome da sua
tabela no canto direito superior do RStudio dentro da aba
Environment. Veja esta área do R na Figura
1 abaixo. Clique na tabela que acabamos de criar chamada
dados.
Figura 1: Tela do painel Environment com a tabela
{dados} carregada no RStudio.
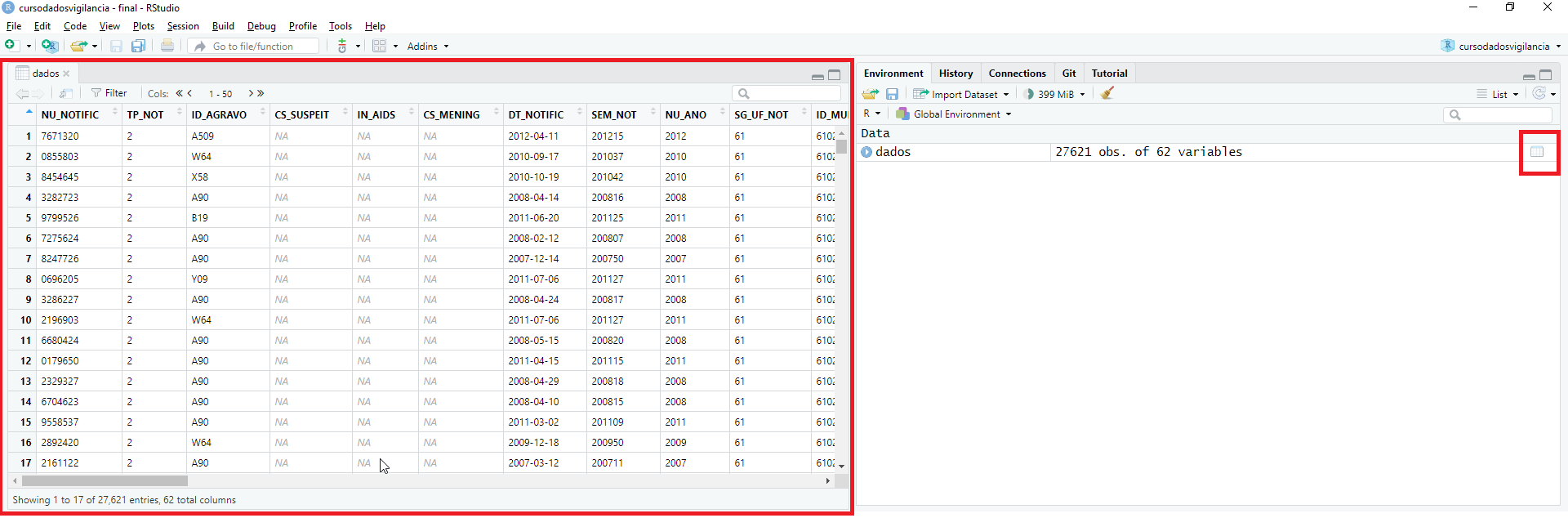
Clicando na tabela {dados}, iremos abrir uma nova aba
com as informações presentes em cada coluna (Figura 2). Utilizando as
barras de rolagens da sua tela para baixo você poderá acessar as
diferentes linhas e colunas de toda tabela {dados} salva no
R.
Figura 2: Tela da IDE RStudio com a tabela
{dados} carregada.
Pronto, agora que conhecemos as variáveis e a estrutura da tabela
{dados} poderemos escolher quais as variáveis serão
necessárias para construção de uma análise dados de vigilância em
saúde.

Lembre-se que ao tentar visualizar bases de dados grandes, a tela irá
mostrar apenas um número máximo de colunas de cada vez. Você pode “mudar
a página” para visualizar mais colunas com os botões >
para ver a próxima “página”, e >> para ir até a
última página. Estes botões estão localizados na porção superior da
visualização de dados.
Acompanhe nas sessões abaixo as medidas mais utilizadas em epidemiologia, como cálculo de frequência, proporção e porcentagem, valores mínimos e máximos, média, mediana, quartis, variância, desvio padrão e medidas de dispersão dos dados.